
Dataset
data = {
"src" : [
"i love you",
"i love myself",
"i like you",
"he love you"
],
"tar" : [
"ich liebe dich",
"ich liebe mich",
"ich mag dich",
"er liebt dich"
]
}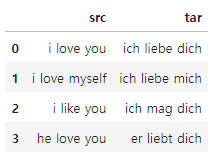
단어 사전
각각 src, tar이다.

Encoder
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
#embedding과 LSTM 준비
self.embed = nn.Embedding(src_tok.n_vocab, hparam['embed_size']) # embed_size = 4
self.rnn = nn.LSTM(input_size=hparam['embed_size'], hidden_size=hparam['embed_size'])
def forward(self, x, h, c):
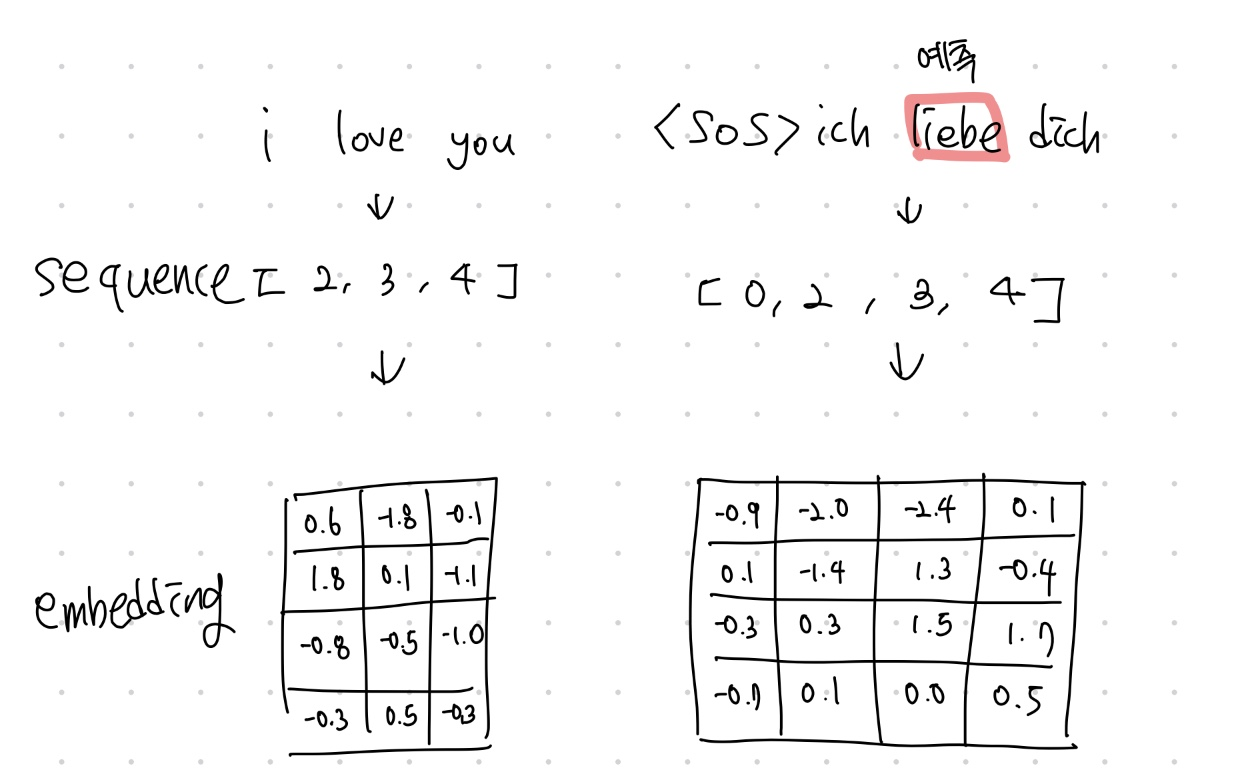
# [i, love, you]가 있다면 i, love, you 순차적으로 들어감 -> (1)
x = self.embed(x)
# (1) -> (embed_size)
x = x.view((1, 1, -1))
# (embed_size) -> (1,1,embed_size)
x, (h, c) = self.rnn(x, (h, c))
# (1,1,embed_size) (1,1,embed_size) (1,1,embed_size)
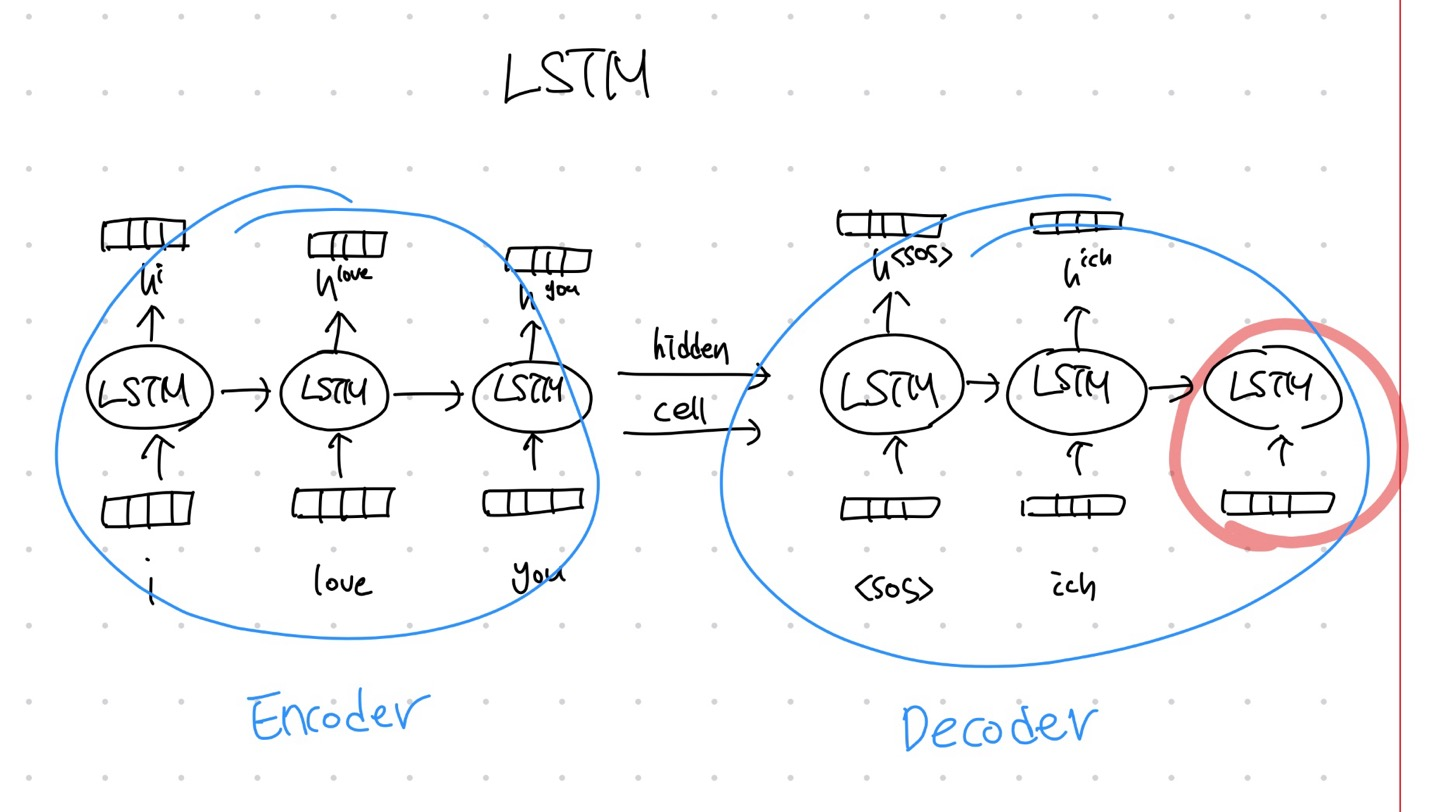
return h, cEncoder는 tar에서 context vector를 뽑아내는 역할을 하며 context vector는 Decoder의 input으로 들어간다.
x에는 한 토큰씩 들어가며 embed_size = 4로 embedding 된다. => 단어들의 유기적인 특성을 4차원으로 표현한다는 뜻
Decoder
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.embed = nn.Embedding(tar_tok.n_vocab, hparam['embed_size']) # embed_size = 4
self.rnn = nn.LSTM(input_size=hparam['embed_size'], hidden_size=hparam['embed_size'])
def forward(self, x, h, c):
# [ich, liebe, dich]가 있다면 ich, liebe, dich 순차적으로 들어감 -> (1)
x = self.embed(x)
# (1) -> (embed_size)
x = x.view((1, 1, -1))
# (embed_size) -> (1,1,embed_size)
x, (h, c) = self.rnn(x, (h, c))
# (1,1,embed_size) (1,1,embed_size) (1,1,embed_size)
return h, cencoder의 context vector를 받아 단어를 추론하는 역할을 한다. \( tar^{t-1} \) 를 기반으로 \( tar^{t} \)를 추론함
학습
Encoder
for epoch in range(500):
loss_avg = []
for batch in range(len(src_data)):
loss = 0
src_train = torch.LongTensor(src_data[batch])
h, c = torch.zeros((1, 1, hparam['embed_size'])), torch.zeros((1, 1, hparam['embed_size']))
# (1,1,embed_size) (1,1,embed_size)
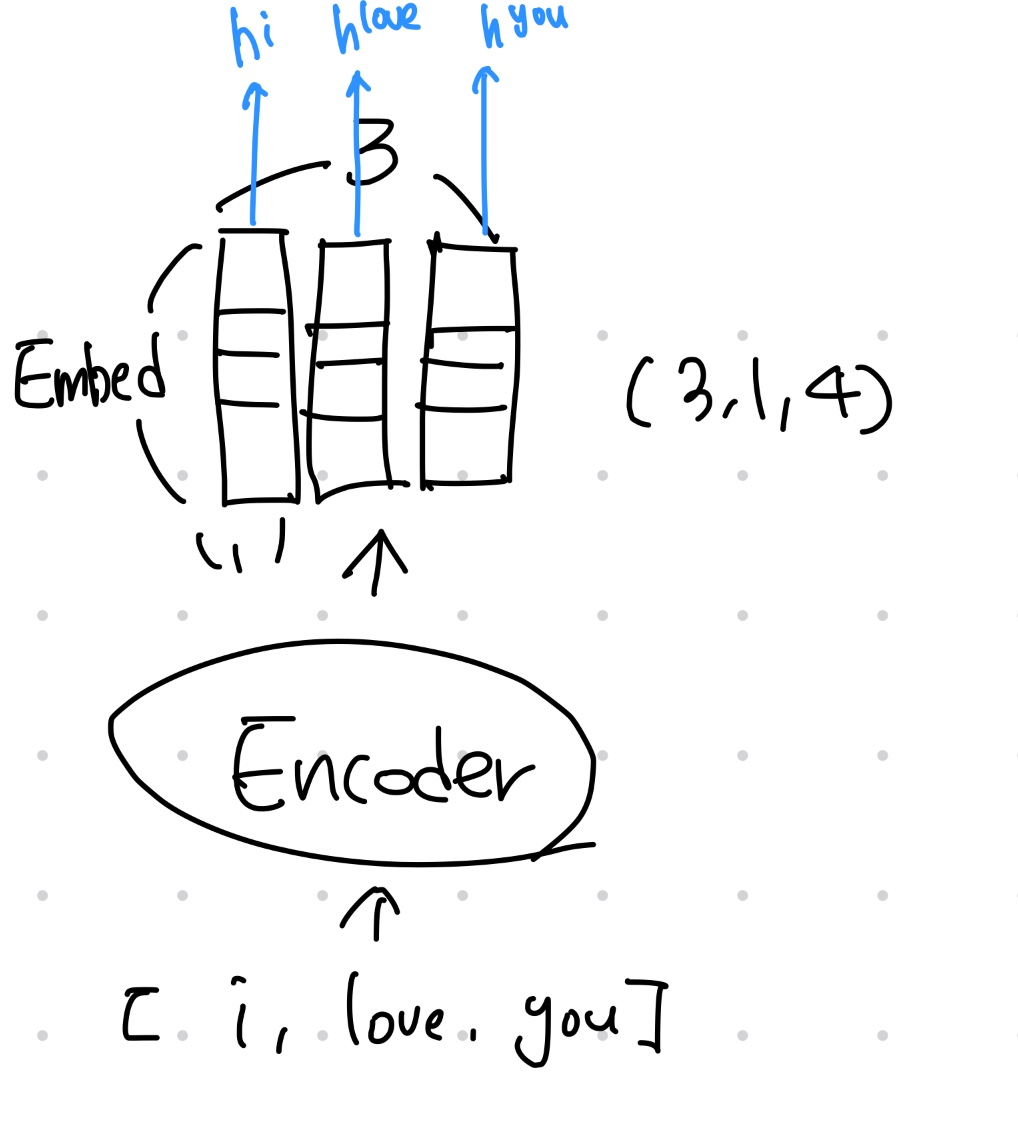
enc_out = torch.Tensor([])
# (src_len, 1, embed_size)
for i in range(len(src_train)):
# x = (1)
h, c = encoder(src_train[i], h, c)
# (1,1,embed_size) (1,1,embed_size)
enc_out = torch.cat((enc_out, h))
Decoder + Attention
for i in range(len(tar_train[:-1])):
h, c = decoder(tar_train[i], h, c)
# (1,1,embed_size) (1,1,embed_size)
score = enc_out.matmul(h.view((1,hparam['embed_size'],1)))
# t 시점 state의 encoder h attention score
# (src_len, 1, 1) = score(hn, stT)
att_dis = F.softmax(score, dim=0)
# Attention Distribution
# (src_len,1,1)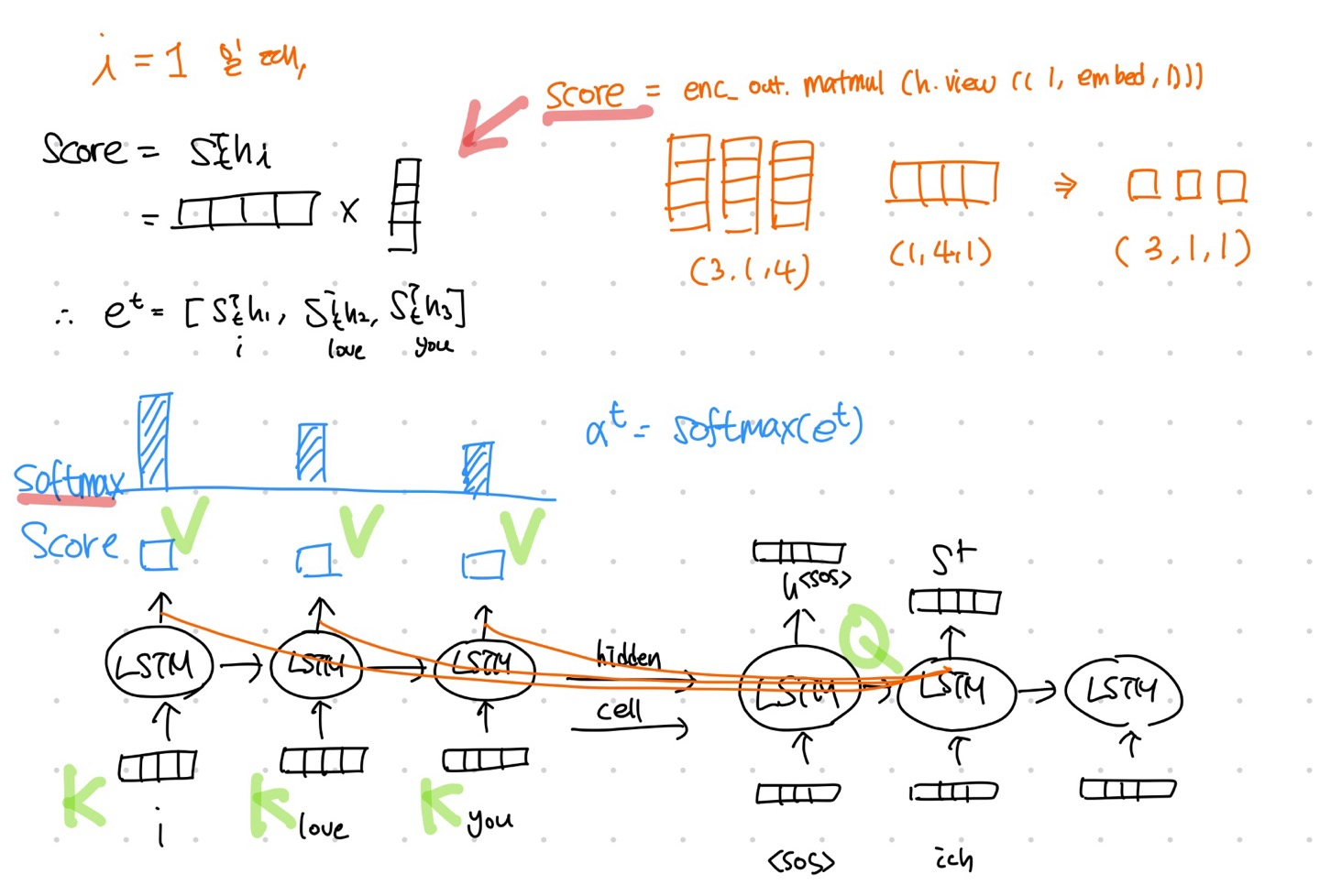
att_v = torch.sum(enc_out * att_dis, dim=0).view(1,1,hparam['embed_size'])
# Attention Value
# (1,1,embed_size)
con = torch.cat((att_v, h), dim=2)
# Concatinate
out = attention(con)
# (1,1,word_cnt)
loss += criterion(out.view((1, -1)), tar_train[i+1].view(1))
sent.append(tar_tok.index2vocab[out.argmax().detach().item()])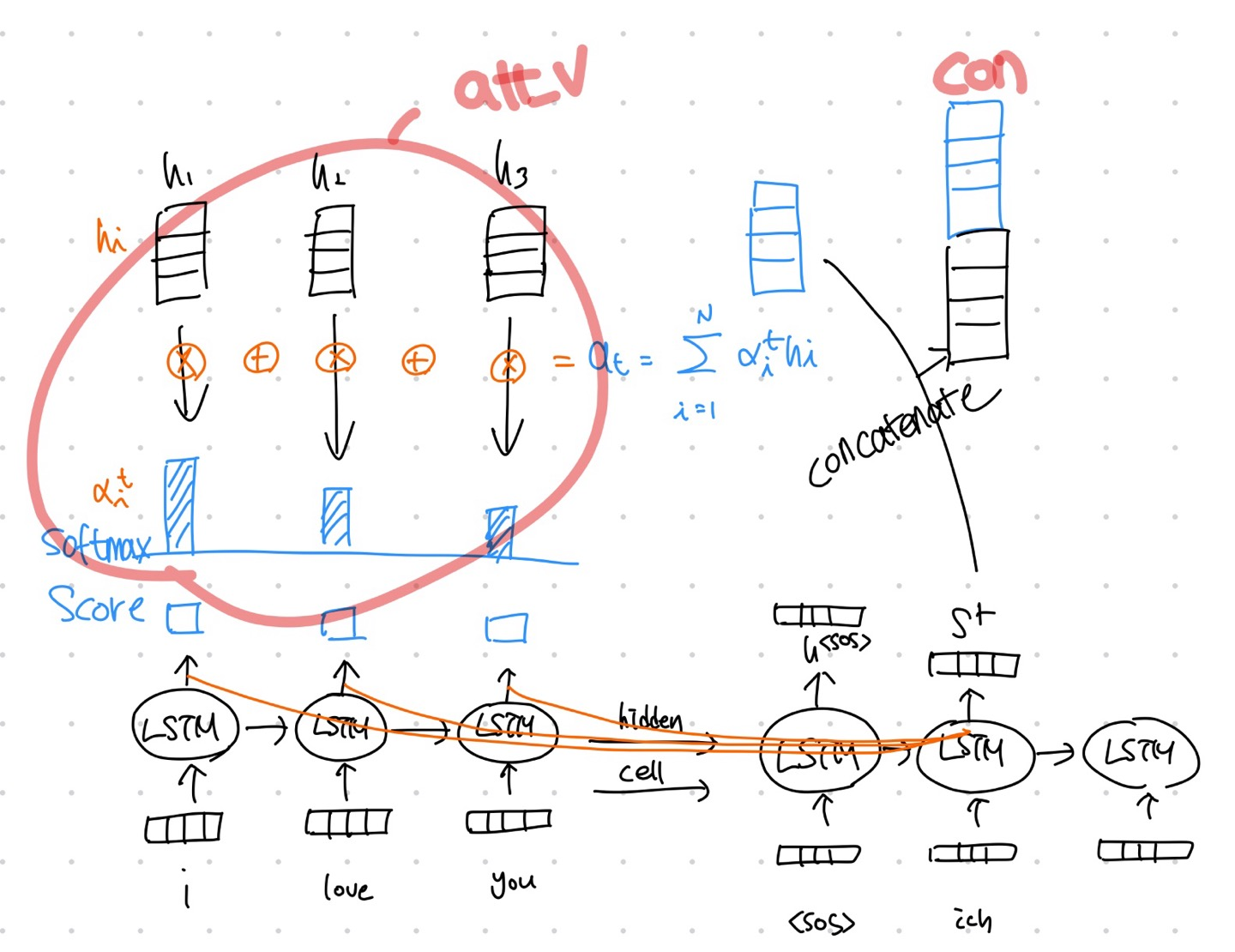
out = attention(con)
# (1,1,word_cnt)
loss += criterion(out.view((1, -1)), tar_train[i+1].view(1))
sent.append(tar_tok.index2vocab[out.argmax().detach().item()])class Attention(nn.Module):
def __init__(self):
super(Attention, self).__init__()
self.wc = nn.Linear(hparam['embed_size'] * 2, hparam['embed_size']) # (embed_size * 2, embed_size) = (8, 4)
self.tanh = nn.Tanh()
self.wy = nn.Linear(hparam['embed_size'], tar_tok.n_vocab) # (embed_size, word_cnt)
def forward(self, x):
# (1,1,embed_size * 2)
x = self.wc(x)
# (1,1,embed_size)
x = self.tanh(x)
# (1,1,embed_size)
x = self.wy(x)
# (1,1,word_cnt)
x = F.log_softmax(x, dim=2)
# (1,1,word_cnt)
return x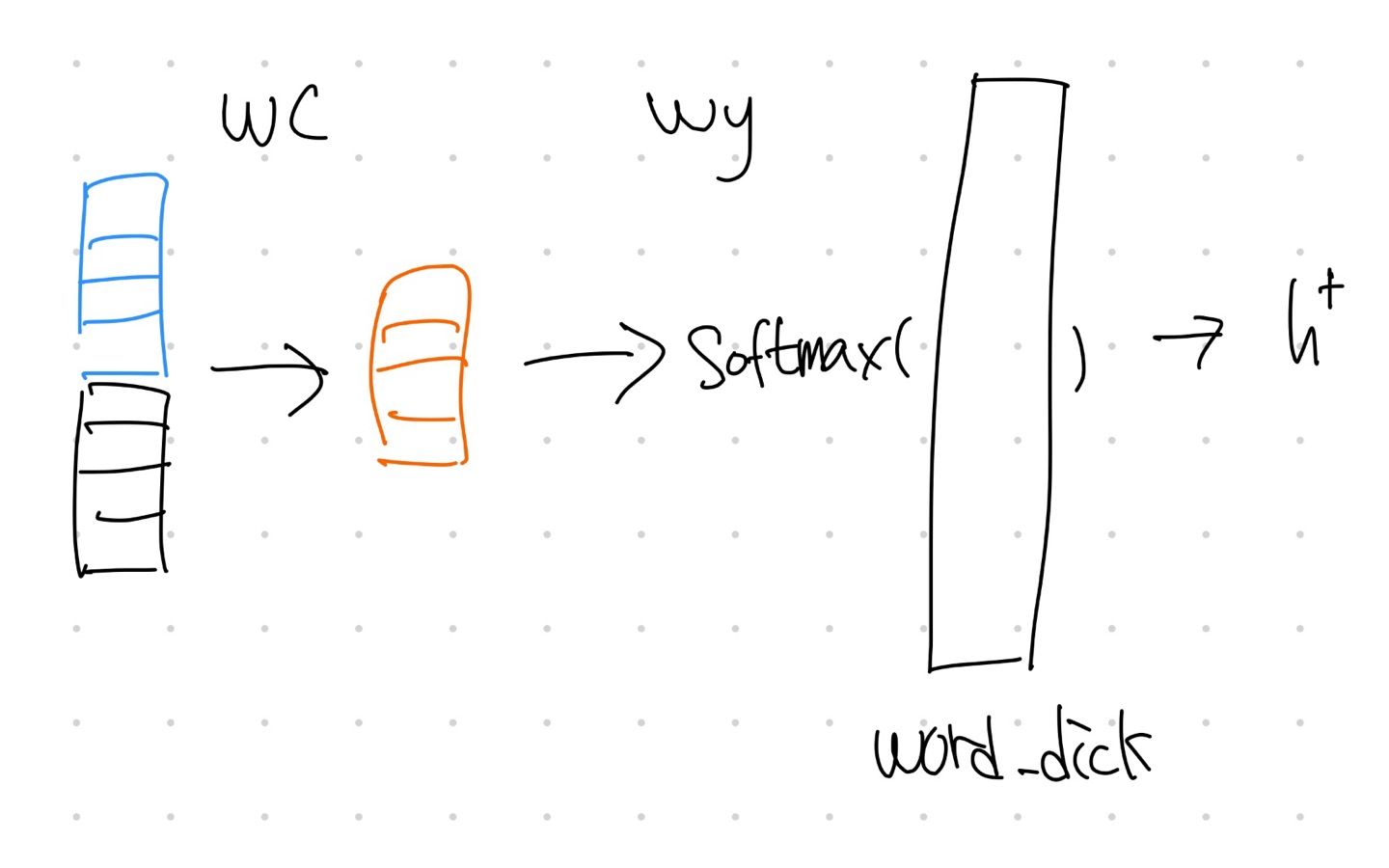
wc는 시점h와 attention정보를 해석하기 위해 사용하며 이후 wy를 통해 다음 단어를 추론한다.
Teacher Forcing
모델 학습 중간에 엉뚱한 값을 추론하고 그 값을 input으로 넣어주면 해당 시점 이후로 모델 학습이 잘 안 될 수 있다. 이러한 문제 때문에 RNN의 모든 step에서는 입력으로 정해진 값만 넣고 이를 Teacher Forcing이라고 한다.
이론과 코드 참고 사이트 Iuna-b 사이트를 참고하여 작성함
https://glee1228.tistory.com/3
'NLP' 카테고리의 다른 글
| GNN(Graph Neural Network)의 기초, 이론, 모델 학습 (0) | 2024.02.14 |
|---|---|
| NER 기초 (0) | 2024.02.08 |
| [NLP] NLP를 위한 CNN (0) | 2023.05.28 |
| [NLP] LSTM(Long Short-Term Memory) (0) | 2023.05.26 |
| [NLP] RNN 실습 - Numpy, keras 구현 (0) | 2023.05.26 |
Dataset
data = {
"src" : [
"i love you",
"i love myself",
"i like you",
"he love you"
],
"tar" : [
"ich liebe dich",
"ich liebe mich",
"ich mag dich",
"er liebt dich"
]
}단어 사전
각각 src, tar이다.
Encoder
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
#embedding과 LSTM 준비
self.embed = nn.Embedding(src_tok.n_vocab, hparam['embed_size']) # embed_size = 4
self.rnn = nn.LSTM(input_size=hparam['embed_size'], hidden_size=hparam['embed_size'])
def forward(self, x, h, c):
# [i, love, you]가 있다면 i, love, you 순차적으로 들어감 -> (1)
x = self.embed(x)
# (1) -> (embed_size)
x = x.view((1, 1, -1))
# (embed_size) -> (1,1,embed_size)
x, (h, c) = self.rnn(x, (h, c))
# (1,1,embed_size) (1,1,embed_size) (1,1,embed_size)
return h, cEncoder는 tar에서 context vector를 뽑아내는 역할을 하며 context vector는 Decoder의 input으로 들어간다.
x에는 한 토큰씩 들어가며 embed_size = 4로 embedding 된다. => 단어들의 유기적인 특성을 4차원으로 표현한다는 뜻
Decoder
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.embed = nn.Embedding(tar_tok.n_vocab, hparam['embed_size']) # embed_size = 4
self.rnn = nn.LSTM(input_size=hparam['embed_size'], hidden_size=hparam['embed_size'])
def forward(self, x, h, c):
# [ich, liebe, dich]가 있다면 ich, liebe, dich 순차적으로 들어감 -> (1)
x = self.embed(x)
# (1) -> (embed_size)
x = x.view((1, 1, -1))
# (embed_size) -> (1,1,embed_size)
x, (h, c) = self.rnn(x, (h, c))
# (1,1,embed_size) (1,1,embed_size) (1,1,embed_size)
return h, cencoder의 context vector를 받아 단어를 추론하는 역할을 한다. tart−1 를 기반으로 tart를 추론함
학습
Encoder
for epoch in range(500):
loss_avg = []
for batch in range(len(src_data)):
loss = 0
src_train = torch.LongTensor(src_data[batch])
h, c = torch.zeros((1, 1, hparam['embed_size'])), torch.zeros((1, 1, hparam['embed_size']))
# (1,1,embed_size) (1,1,embed_size)
enc_out = torch.Tensor([])
# (src_len, 1, embed_size)
for i in range(len(src_train)):
# x = (1)
h, c = encoder(src_train[i], h, c)
# (1,1,embed_size) (1,1,embed_size)
enc_out = torch.cat((enc_out, h))Decoder + Attention
for i in range(len(tar_train[:-1])):
h, c = decoder(tar_train[i], h, c)
# (1,1,embed_size) (1,1,embed_size)
score = enc_out.matmul(h.view((1,hparam['embed_size'],1)))
# t 시점 state의 encoder h attention score
# (src_len, 1, 1) = score(hn, stT)
att_dis = F.softmax(score, dim=0)
# Attention Distribution
# (src_len,1,1) att_v = torch.sum(enc_out * att_dis, dim=0).view(1,1,hparam['embed_size'])
# Attention Value
# (1,1,embed_size)
con = torch.cat((att_v, h), dim=2)
# Concatinate
out = attention(con)
# (1,1,word_cnt)
loss += criterion(out.view((1, -1)), tar_train[i+1].view(1))
sent.append(tar_tok.index2vocab[out.argmax().detach().item()]) out = attention(con)
# (1,1,word_cnt)
loss += criterion(out.view((1, -1)), tar_train[i+1].view(1))
sent.append(tar_tok.index2vocab[out.argmax().detach().item()])class Attention(nn.Module):
def __init__(self):
super(Attention, self).__init__()
self.wc = nn.Linear(hparam['embed_size'] * 2, hparam['embed_size']) # (embed_size * 2, embed_size) = (8, 4)
self.tanh = nn.Tanh()
self.wy = nn.Linear(hparam['embed_size'], tar_tok.n_vocab) # (embed_size, word_cnt)
def forward(self, x):
# (1,1,embed_size * 2)
x = self.wc(x)
# (1,1,embed_size)
x = self.tanh(x)
# (1,1,embed_size)
x = self.wy(x)
# (1,1,word_cnt)
x = F.log_softmax(x, dim=2)
# (1,1,word_cnt)
return xwc는 시점h와 attention정보를 해석하기 위해 사용하며 이후 wy를 통해 다음 단어를 추론한다.
Teacher Forcing
모델 학습 중간에 엉뚱한 값을 추론하고 그 값을 input으로 넣어주면 해당 시점 이후로 모델 학습이 잘 안 될 수 있다. 이러한 문제 때문에 RNN의 모든 step에서는 입력으로 정해진 값만 넣고 이를 Teacher Forcing이라고 한다.
이론과 코드 참고 사이트 Iuna-b 사이트를 참고하여 작성함
https://glee1228.tistory.com/3
'NLP' 카테고리의 다른 글
| GNN(Graph Neural Network)의 기초, 이론, 모델 학습 (0) | 2024.02.14 |
|---|---|
| NER 기초 (0) | 2024.02.08 |
| [NLP] NLP를 위한 CNN (0) | 2023.05.28 |
| [NLP] LSTM(Long Short-Term Memory) (0) | 2023.05.26 |
| [NLP] RNN 실습 - Numpy, keras 구현 (0) | 2023.05.26 |