
코퍼스(Corpus)
- 코퍼스는 말뭉치로 자연언어 연구를 위해 특정한 목적을 가지고 언어의 표본을 추출한 집합이다.
- 글 또는 말 텍스트를 모아 놓은 것
- 둘 이상의 코퍼스가 존재하면 코포라(Corpora)라고 부름
- 구성된 언어를 기준으로 단일 언어 코퍼스, 이중 언어 코퍼스(한글, 영어), 다국어 코퍼스(번역)로 나눌 수 있음
필요 이유
- 코퍼스를 통해 자연어에 대한 빈도 분포, 단어의 동시 발생 등과 같은 통계적인 분석 가능
- 다양한 자연어처리 과정에서 자연어 데이터에 대한 언어 규칙을 정의하고 검증할 수 있음
- ex) 사투리의 규칙
- 규칙 기반 시스템의 도움으로 언어에 따라 각 언어에 대한 언어 규칙을 정의할 수 있게 함
수집
- 오픈소스 코퍼스
- 다양한 웹사이트에서 크롤링하여 데이터 수집
- 저작권 문제, 트래픽 문제등을 확인하여 크롤링해야 함
코퍼스 분석
음성데이터(Dialog)
- 각 데이터의 음성 이해에 대한 분석 및 대화 분석 필요
- 생략, 대명사 등이 많기 때문에 문맥을 잘 판단해야 함
텍스트데이터
- 일반적으로 코퍼스에 단어가 몇 개 나오는지, 코퍼스 내에 있는 특정 단어의 빈도수가 얼마인지 분석
- 코퍼스에 노이즈가 있다면 제거
- 분석 방법, task에 따라 노이지의 정의가 달라질 수 있음
NLTK
- NLTK(Natural Language Toolkit)는 python으로 작성된 영어 자연어 처리를 위한 라이브러리 및 프로그램 모음
- 다양한 기능을 가지고 있으며 교육용 뿐만 아니라 실무 및 연구에서도 많이 사용함
- 50 종류 이상의 코포라와 어휘 자원을 가지고 있고 이를 가지고 실습이 가능함
내장 코포라

실습
코포라 가져오기
import nltk
from nltk.corpus import brown as cb
from nltk.corpus import gutenberg as cg
nltk.download('brown')
nltk.download('gutenberg')
.fileids()
실습 코포라의 코퍼스 파일 확인하기
cb.fileids()
cg.fileids()

.categories()
코포라의 카테코리 나열
cb.categories()
.words()
코포라의 전체 단어 나열
cb.words()
categories의 인자를 통해 지정 category의 단어 나열
cb.words(categories='news')[:20]
nltk.Text()
특정 코퍼스(문서) 가져오기, Text 클래스는 문서 분석에 유용한 메소드를 가지고 있음
cb.words('ca01')
raw_text = nltk.Text(cb.words('ca01'))
raw_text
Text().concordance()
특정 단어가 들어간 문장 추출, Text 클래스 메소드로 Text로 생성해야지만 쓸 수 있음
raw_text.concordance("The")
.raw()
가공 전 데이터 가져오기 html 태그가 들어있음
raw_text = cb.raw('ca02')
raw_text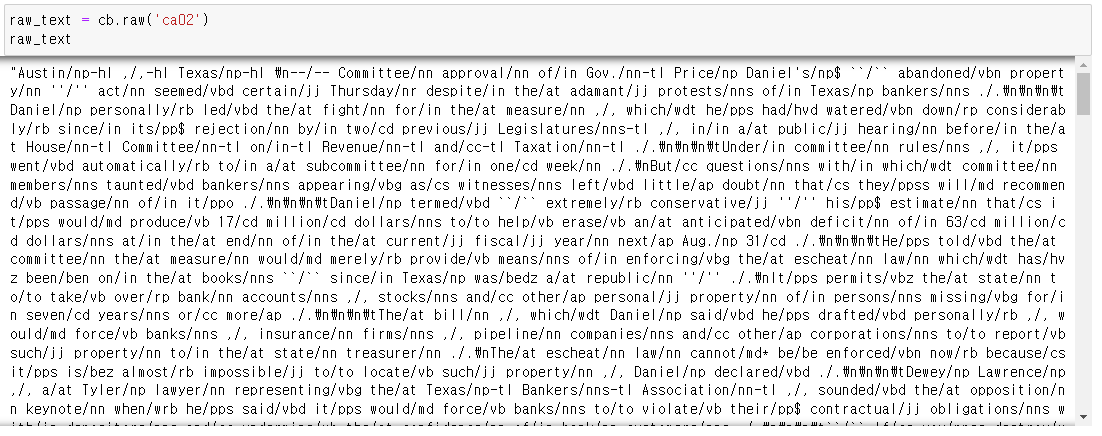
데이터 전처리
- 사용자의 task에 맞게 주어진 데이터를 변형 또는 가공하는 과정
- 자연어처리뿐만 아니라 산업 전반적으로 매우 중요한 과정
- 예전에는 Norn 추출을 통한 방법이 좋았지만 딥러닝의 발달로 pull context를 사용하게 됨\
과정
| 토큰화 | 정제 | 정규화 |
- 토큰화
- 목적에 따라 단어, 문장, 구 단위로 나눔
- 상황과 목적에 맞는 토큰화 툴을 사용해야 함
- 구두점 또는 특수문자가 이미 포함된 단어의 경우 따로 Dict에 단어를 정의해야 함(ph.D 등)
- 정제
- 데이터에서 손상되거나 부정확한 부분을 감지하고 수정하는 과정
- 데이터의 불완전하거나 부정확하거나 관련이 없는 부분을 식별한 뒤에 해당 부분을 대체, 수정하는 과정
- 정규화
- 텍스트 데이터에서 정규화는 표현 방법이 다른 단어들을 통합시켜 같은 단어로 통합시키는 과정
- wanted -> want, programming -> program
- 어간 추출
- 어간 추출로 접미사를 삭제하거나 대체하여 문장의 각 단어를 어근 형태로 변환하는 과정
- 접미사를 삭제 또는 대체하는 과정이므로 결과물이 사전에 없을 수 있음
- 다양한 어간 추출 툴킷이 존재하지만 언어별로 잘 동작하지 않을 수 있음
- 텍스트 데이터에서 정규화는 표현 방법이 다른 단어들을 통합시켜 같은 단어로 통합시키는 과정
실습
sent_tokenize()
텍스트를 문장 단위로 토큰화함
nltk.download('punkt')
from nltk.tokenize import sent_tokenize
text = 'NLTK is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active discussion forum.'
sent_tokenize(text)
word_tokenize()
단어 단위로 문장을 토큰화함
from nltk.tokenize import word_tokenize
text = 'NLTK is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active discussion forum.'
word_tokenize(text)
WordPunctTokenizer().tokenize()
punck를 기준으로 토큰화함
from nltk.tokenize import WordPunctTokenizer
text = "If you really want to do something, you'll find a way. If you don't, you'll find an excuse"
WordPunctTokenizer().tokenize(text)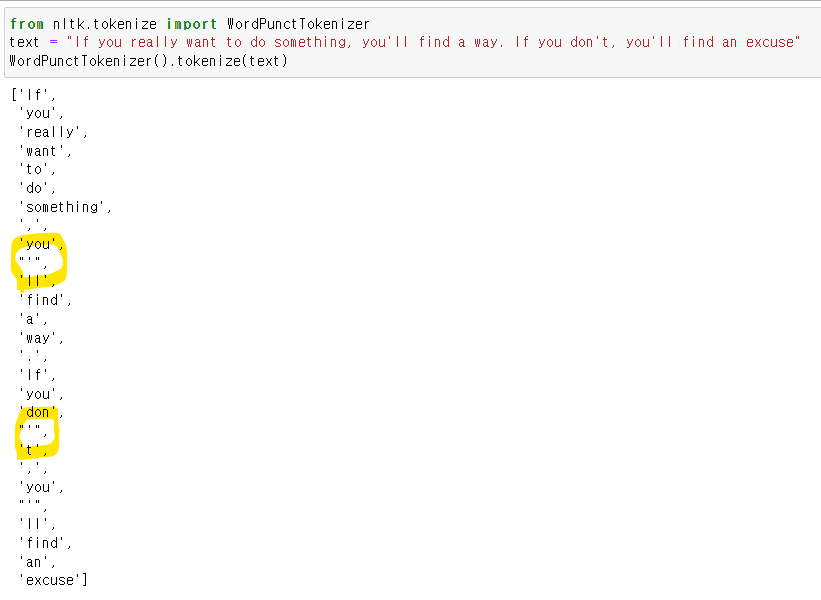
.lower()
영어권에서는 대소문자를 일반적으로 소문자로 변환함
text = "If You Really Want To Do Something, You'll Find a Way. If You Don't, You'll Find An Excuse"
text = text.lower()
text
PoterStemmer
어간 추출기 1 - 성능이 그다지 좋진 않음
from nltk.stem import PorterStemmer
text = 'NLTK is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active discussion forum.'
[PorterStemmer().stem(word) for word in text.split()]
사전에 없는 단어가 생길 수 있음
LancasterStemmer
어간 추출기-2
from nltk.stem import LancasterStemmer
text = 'NLTK is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active discussion forum.'
[LancasterStemmer().stem(word) for word in text.split()]pos_tag
단어의 형태가 같아도 품사에 따라 의미가 달라질 수 있으며 품사를 태그 해줌
아래에 맞게 분류함
https://cs.nyu.edu/~grishman/jet/guide/PennPOS.html
Penn part-of-speech tags
cs.nyu.edu
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
text = "She finally completed Ph.D. degree"
word_token = word_tokenize(text)
print(pos_tag(word_token))

WordNetLemmatizer()
품사를 지정하여 표제어 추출하기
from nltk.stem import WordNetLemmatizer
text = "She finally completed Ph.D. degree"
[WordNetLemmatizer().lemmatize(word, 'v') for word in text.split()]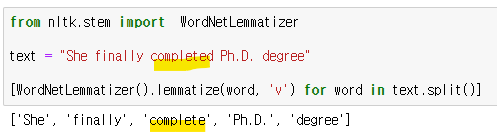
stopwords()
불용어를 처리해 줌, 불용어란 문장 현성에 있어서 중요하나 구문론적 가치를 지니고 있지만 무시하거나 최소한의 의미적 가치를 지닌 단어
import nltk
from nltk.corpus import stopwords
stopwl = stopwords.words('english')
stopwl
'NLP' 카테고리의 다른 글
| [NLP] RNN 실습 - Numpy, keras 구현 (0) | 2023.05.26 |
|---|---|
| [NLP] RNN(Recurrent Neural Network) (0) | 2023.05.26 |
| [NLP] 한국어 자연어처리 (0) | 2023.04.03 |
| [NLP] 자연어처리의 이해 (0) | 2023.04.03 |
| [RNN] Transformer (0) | 2023.01.31 |
코퍼스(Corpus)
- 코퍼스는 말뭉치로 자연언어 연구를 위해 특정한 목적을 가지고 언어의 표본을 추출한 집합이다.
- 글 또는 말 텍스트를 모아 놓은 것
- 둘 이상의 코퍼스가 존재하면 코포라(Corpora)라고 부름
- 구성된 언어를 기준으로 단일 언어 코퍼스, 이중 언어 코퍼스(한글, 영어), 다국어 코퍼스(번역)로 나눌 수 있음
필요 이유
- 코퍼스를 통해 자연어에 대한 빈도 분포, 단어의 동시 발생 등과 같은 통계적인 분석 가능
- 다양한 자연어처리 과정에서 자연어 데이터에 대한 언어 규칙을 정의하고 검증할 수 있음
- ex) 사투리의 규칙
- 규칙 기반 시스템의 도움으로 언어에 따라 각 언어에 대한 언어 규칙을 정의할 수 있게 함
수집
- 오픈소스 코퍼스
- 다양한 웹사이트에서 크롤링하여 데이터 수집
- 저작권 문제, 트래픽 문제등을 확인하여 크롤링해야 함
코퍼스 분석
음성데이터(Dialog)
- 각 데이터의 음성 이해에 대한 분석 및 대화 분석 필요
- 생략, 대명사 등이 많기 때문에 문맥을 잘 판단해야 함
텍스트데이터
- 일반적으로 코퍼스에 단어가 몇 개 나오는지, 코퍼스 내에 있는 특정 단어의 빈도수가 얼마인지 분석
- 코퍼스에 노이즈가 있다면 제거
- 분석 방법, task에 따라 노이지의 정의가 달라질 수 있음
NLTK
- NLTK(Natural Language Toolkit)는 python으로 작성된 영어 자연어 처리를 위한 라이브러리 및 프로그램 모음
- 다양한 기능을 가지고 있으며 교육용 뿐만 아니라 실무 및 연구에서도 많이 사용함
- 50 종류 이상의 코포라와 어휘 자원을 가지고 있고 이를 가지고 실습이 가능함
내장 코포라
실습
코포라 가져오기
import nltk
from nltk.corpus import brown as cb
from nltk.corpus import gutenberg as cg
nltk.download('brown')
nltk.download('gutenberg').fileids()
실습 코포라의 코퍼스 파일 확인하기
cb.fileids()
cg.fileids().categories()
코포라의 카테코리 나열
cb.categories()
.words()
코포라의 전체 단어 나열
cb.words()categories의 인자를 통해 지정 category의 단어 나열
cb.words(categories='news')[:20]nltk.Text()
특정 코퍼스(문서) 가져오기, Text 클래스는 문서 분석에 유용한 메소드를 가지고 있음
cb.words('ca01')
raw_text = nltk.Text(cb.words('ca01'))
raw_textText().concordance()
특정 단어가 들어간 문장 추출, Text 클래스 메소드로 Text로 생성해야지만 쓸 수 있음
raw_text.concordance("The").raw()
가공 전 데이터 가져오기 html 태그가 들어있음
raw_text = cb.raw('ca02')
raw_text데이터 전처리
- 사용자의 task에 맞게 주어진 데이터를 변형 또는 가공하는 과정
- 자연어처리뿐만 아니라 산업 전반적으로 매우 중요한 과정
- 예전에는 Norn 추출을 통한 방법이 좋았지만 딥러닝의 발달로 pull context를 사용하게 됨\
과정
| 토큰화 | 정제 | 정규화 |
- 토큰화
- 목적에 따라 단어, 문장, 구 단위로 나눔
- 상황과 목적에 맞는 토큰화 툴을 사용해야 함
- 구두점 또는 특수문자가 이미 포함된 단어의 경우 따로 Dict에 단어를 정의해야 함(ph.D 등)
- 정제
- 데이터에서 손상되거나 부정확한 부분을 감지하고 수정하는 과정
- 데이터의 불완전하거나 부정확하거나 관련이 없는 부분을 식별한 뒤에 해당 부분을 대체, 수정하는 과정
- 정규화
- 텍스트 데이터에서 정규화는 표현 방법이 다른 단어들을 통합시켜 같은 단어로 통합시키는 과정
- wanted -> want, programming -> program
- 어간 추출
- 어간 추출로 접미사를 삭제하거나 대체하여 문장의 각 단어를 어근 형태로 변환하는 과정
- 접미사를 삭제 또는 대체하는 과정이므로 결과물이 사전에 없을 수 있음
- 다양한 어간 추출 툴킷이 존재하지만 언어별로 잘 동작하지 않을 수 있음
- 텍스트 데이터에서 정규화는 표현 방법이 다른 단어들을 통합시켜 같은 단어로 통합시키는 과정
실습
sent_tokenize()
텍스트를 문장 단위로 토큰화함
nltk.download('punkt')
from nltk.tokenize import sent_tokenize
text = 'NLTK is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active discussion forum.'
sent_tokenize(text)word_tokenize()
단어 단위로 문장을 토큰화함
from nltk.tokenize import word_tokenize
text = 'NLTK is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active discussion forum.'
word_tokenize(text)
WordPunctTokenizer().tokenize()
punck를 기준으로 토큰화함
from nltk.tokenize import WordPunctTokenizer
text = "If you really want to do something, you'll find a way. If you don't, you'll find an excuse"
WordPunctTokenizer().tokenize(text)
.lower()
영어권에서는 대소문자를 일반적으로 소문자로 변환함
text = "If You Really Want To Do Something, You'll Find a Way. If You Don't, You'll Find An Excuse"
text = text.lower()
textPoterStemmer
어간 추출기 1 - 성능이 그다지 좋진 않음
from nltk.stem import PorterStemmer
text = 'NLTK is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active discussion forum.'
[PorterStemmer().stem(word) for word in text.split()]사전에 없는 단어가 생길 수 있음
LancasterStemmer
어간 추출기-2
from nltk.stem import LancasterStemmer
text = 'NLTK is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active discussion forum.'
[LancasterStemmer().stem(word) for word in text.split()]pos_tag
단어의 형태가 같아도 품사에 따라 의미가 달라질 수 있으며 품사를 태그 해줌
아래에 맞게 분류함
https://cs.nyu.edu/~grishman/jet/guide/PennPOS.html
Penn part-of-speech tags
cs.nyu.edu
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
text = "She finally completed Ph.D. degree"
word_token = word_tokenize(text)
print(pos_tag(word_token))
WordNetLemmatizer()
품사를 지정하여 표제어 추출하기
from nltk.stem import WordNetLemmatizer
text = "She finally completed Ph.D. degree"
[WordNetLemmatizer().lemmatize(word, 'v') for word in text.split()]stopwords()
불용어를 처리해 줌, 불용어란 문장 현성에 있어서 중요하나 구문론적 가치를 지니고 있지만 무시하거나 최소한의 의미적 가치를 지닌 단어
import nltk
from nltk.corpus import stopwords
stopwl = stopwords.words('english')
stopwl'NLP' 카테고리의 다른 글
| [NLP] RNN 실습 - Numpy, keras 구현 (0) | 2023.05.26 |
|---|---|
| [NLP] RNN(Recurrent Neural Network) (0) | 2023.05.26 |
| [NLP] 한국어 자연어처리 (0) | 2023.04.03 |
| [NLP] 자연어처리의 이해 (0) | 2023.04.03 |
| [RNN] Transformer (0) | 2023.01.31 |