
순환신경망을 사용하지 않고 attention으로 구성된 인코더 디코더 모델이다. 단어간의 상관관계로 문장을 해석할 수 있다면 순차적으로 문장 패턴을 인식하는 RNN은 사용할 필요가 없다.
트랜스포머는 다음과 같이 크기를 조정한 내적으로 셀프 어텐션값을 계산한다.
$$ attention(Q,K,V)=softmax( \frac{QK^{T}}{ \sqrt{d_{k}} } )V $$
구조

인코더는 인코더 블록을 N번 반복하고 디코더는 디코더 블록을 N번 반복하는 구조로 되어있다. 모든 단어를 한꺼번에 입력하기 때문에 단어의 순서 정보를 명시해줘야한다. 그렇기 때문에 위치 인코딩 정보를 단어와 함께 입력한다.
멀티 헤드 어텐션
인코더 블록은 multi-head-attention계층과 완전 연결 계층으로 구성되며 각 계층은 잔차 연결을 가지고 계층 정규화를 수행한다. 디코더 블록은 셀프 어텐션을 할 때 입력 데이터의 앞쪽 단어와 어텐션을 계산하도록 제안하기 위해 뒤쪽 단어를 마스크 처리한다. 이를 masked multi-head attention이라고 한다.
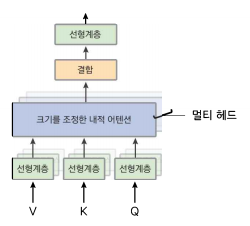
멀티 헤드 어텐션은 한 단어에 대해 여러 관점으로 어텐션을 살펴보기 위해 여러 번 어텐션을 수행한다. 어텐션을 여러 번 실행하는 대신 단어의 차원을 축소하므로 연산량이 많이 늘지는 않는다. 예를 들어 단어가 512차원에 멀티 헤드 개수가 8개라면 단어를 64차원(512차원 / 8)으로 줄이고 어텐션을 8번 병렬 실행해서 그 결과를 결합한다.
영어를 불어로 기계 번역을 할 때 인코더 it의 셀프 어텐션 분포이다. 문장의 의미에 따라 it이 어떤 단어를 가리키는지 어텐션을 통해 계산하고 있음을 알 수 있다.

'NLP' 카테고리의 다른 글
| [NLP] 한국어 자연어처리 (0) | 2023.04.03 |
|---|---|
| [NLP] 자연어처리의 이해 (0) | 2023.04.03 |
| [NLP] Seq2Seq with Attention (0) | 2023.01.31 |
| [RNN] Backpropagation through time (0) | 2023.01.30 |
| [RNN] RNN 모델 종류 (0) | 2023.01.26 |