
728x90
Overfitting 막는 방법
1. 데이터의 양 늘리기
- 데이터의 양이 적은 경우 특정 패턴이나 노이즈를 쉽게 암기하게 되어 과적합 현상이 발생할 수 있음
- 데이터의 양을 늘려 일반적인 패턴을 학습하게 해야함
- 데이터의 양이 적다면 기존의 데이터를 변형하여 양을 늘리기도 함 (Data Augmentation)
2. 모델 복잡도 줄이기
- 복잡도는 hidden layer나 매개변수의 수 등으로 결정됨
- 이를 적게 하여 복잡도를 줄인다
- 모델 수용력 = 모델에 있는 매개변수들의 수
3. 가중치 규제 적용하기 (Regularization)
https://pasongsong.tistory.com/122
- 모델 복잡도 줄이기와 같은 방법으로 복잡한 모델을 간단하게 만드는 것
- L1 규제
- 가중치의 w들의 절대값 합계를 비용 함수에 추가하는 것
- L2 규제
- 모든 가중치 w들의 제곱합을 비용 함수에 추가하는 것
4. 드롭아웃 (Dropout)
- 학습 과정에서 일부 신경망은 사용하지 않는 것
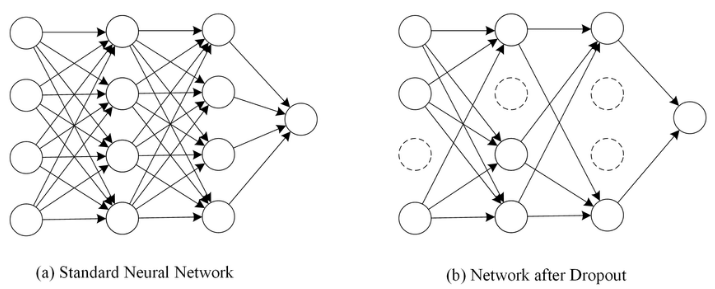
- 비율을 정해 학습 마다 랜덤으로 비율만큼의 뉴런을 사용하지 않고 학습함
- 학습에만 사용하고 예측에는 사용하지 않음
- 특정 조합의 의존을 방지하고 매번 랜덤 선택으로 뉴런을 사용하지 않아 서로 다른 신경망을 앙상블 하여 사용하는 것 같은 효과를 냄
5. Cross Validation
728x90
'Machine Learning > 이론' 카테고리의 다른 글
| [ML] 교차 검증 Cross Validatoin (0) | 2022.08.22 |
|---|---|
| [ML] 규제 Regularization (0) | 2022.08.18 |
| 머신러닝 Machine Learning Bias, Variance (0) | 2022.08.17 |
| [ML] Overfitting, Underfitting (0) | 2022.08.17 |
| Hypothesis and Inference, p-value (0) | 2022.08.11 |