Apriori 이란? - 장바구니, 연관성 분석
https://pasongsong.tistory.com/537
Association Rule 연관 규칙
Association Rule 추천 시스템에서 Baseline이 되는 것으로 어떤 사건이 얼마나 자주 함께 발생하는 지를 수치화 하는 방법이다. items 사이의 관계를 수치화 하는 방법으로 items끼리의 상호 연관관계를
pasongsong.tistory.com
Association Rule을 적용하기 위해서는 각 item이 item Set에서 어떤 빈도로 출현했는지, 어떤 item과 함께 나왔는지 파악
해야 한다.
Dataset의 모든 후보 itemset에 대해 하나하나 검사하는 것은 굉장히 비효율적이며 시간이 오래 걸린다. 이러한 문제를 해결하기 위해 Apriorim, FP-Growth Algorithm이 제시되었다.
Apriori Algorithm
빈발항목집합(최소 지지도 이상을 갖는 집합)을 추출하는 것이 원리이며 모든 항목집합에 대해 복잡한 계산량을 줄이기 위해 최소 지지도를 정하여 그 이상의 값만 찾은 후 연관 규칙을 생성한다.
- 연관규칙(Association Rule) 탐사의 대표적인 알고리즘
- item의 출현 빈도를 기반으로 각 데이터 간의 연관관계를 탐색함

분석 예시
itemset
| ID | itemset(방문했던 나라) |
| lim | 독일, 스위스, 스페인 |
| song | 스위스, 홍콩 |
| ko | 스위스, 페로 제도 |
| kim | 독일, 스위스, 홍콩 |
| jeong | 독일, 페로 제도 |
| choi | 스위스, 페로 제도 |
| lee | 독일, 페로 제도 |
| jang | 독일, 스위스, 페로 제도, 스페인 |
| park | 독일, 스위스, 페로 제도 |
item의 빈도 \( C_{1}, L_{1} \)
| itemset | count |
| 독일 | 6 |
| 스위스 | 7 |
| 페로 제도 | 6 |
| 홍콩 | 2 |
| 스페인 | 2 |
minimum support는 사용자가 설정하는 것으로 count가 2 이상으로 설정하겠음
minimum support는 코드상에서 아래와 같이 설정되는 것 같음
IDMMX.DM_RuleSettings()..DM_setMinSupport(25)
# https://www.ibm.com/docs/en/db2/11.1?topic=rules-defining-minimum-support모든 아이템이 1이 넘기 때문에 \( L_{1} \)은 아래의 표와 같다.
| itemset | count |
| 독일 | 6 |
| 스위스 | 7 |
| 페로 제도 | 6 |
| 홍콩 | 2 |
| 스페인 | 2 |
\( L_{1} \)의 빈도 \( C_{2}, L_{2} \)
\( C_{2} \)
| itemset | count |
| {독일, 스위스} | 4 |
| {독일, 페로 제도} | 4 |
| {독일, 홍콩} | 1 |
| {독일, 스페인} | 2 |
| {스위스, 페로 제도} | 4 |
| {스위스, 홍콩} | 2 |
| {스위스, 스페인} | 2 |
| {페로 제도, 홍콩} | 0 |
| {페로 제도, 스페인} | 1 |
| {홍콩, 스페인} | 0 |
\( L_{2} \)
| itemset | count |
| {독일, 스위스} | 4 |
| {독일, 페로 제도} | 4 |
| {독일, 스페인} | 2 |
| {스위스, 페로 제도} | 4 |
| {스위스, 홍콩} | 2 |
| {스위스, 스페인} | 2 |
\( L_{2} \)의 빈도 \( L_{3} \)
\( C_{3} \)에서 필요하지 않은( minimum support 조건을 만족하지 않은) Subset을 가지치기 Pruning 하면 결과는 아래와 같다.
위에도 전부 유효하지 않은 Subset을 Pruning 한 결과이다.
| itemset | count |
| {독일, 스위스, 페로 제도} | 2 |
| {독일, 스위스, 스페인} | 2 |
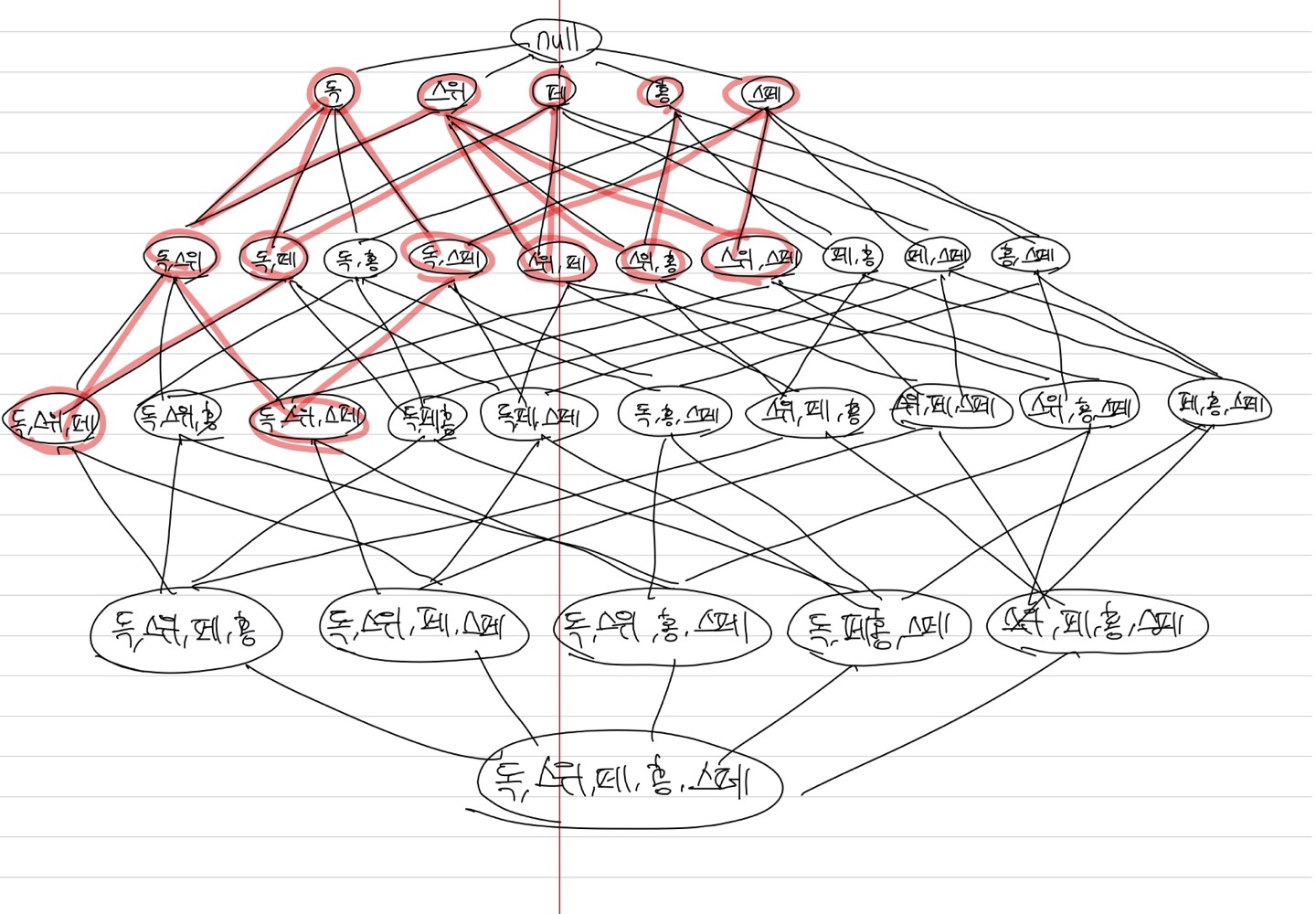
이것을 맨 처음에 예시로 나왔던 사진으로 나타내면 아래와 같다.
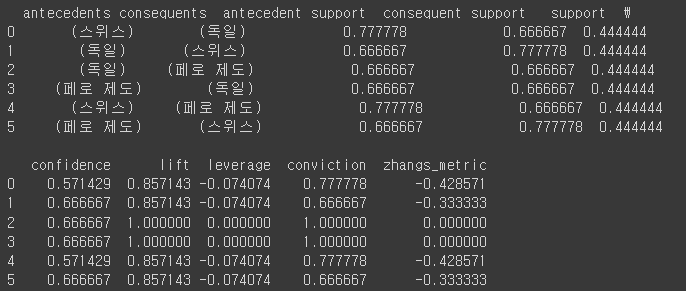
associate rule을 적용한 후는 다음과 같이 정리된다.
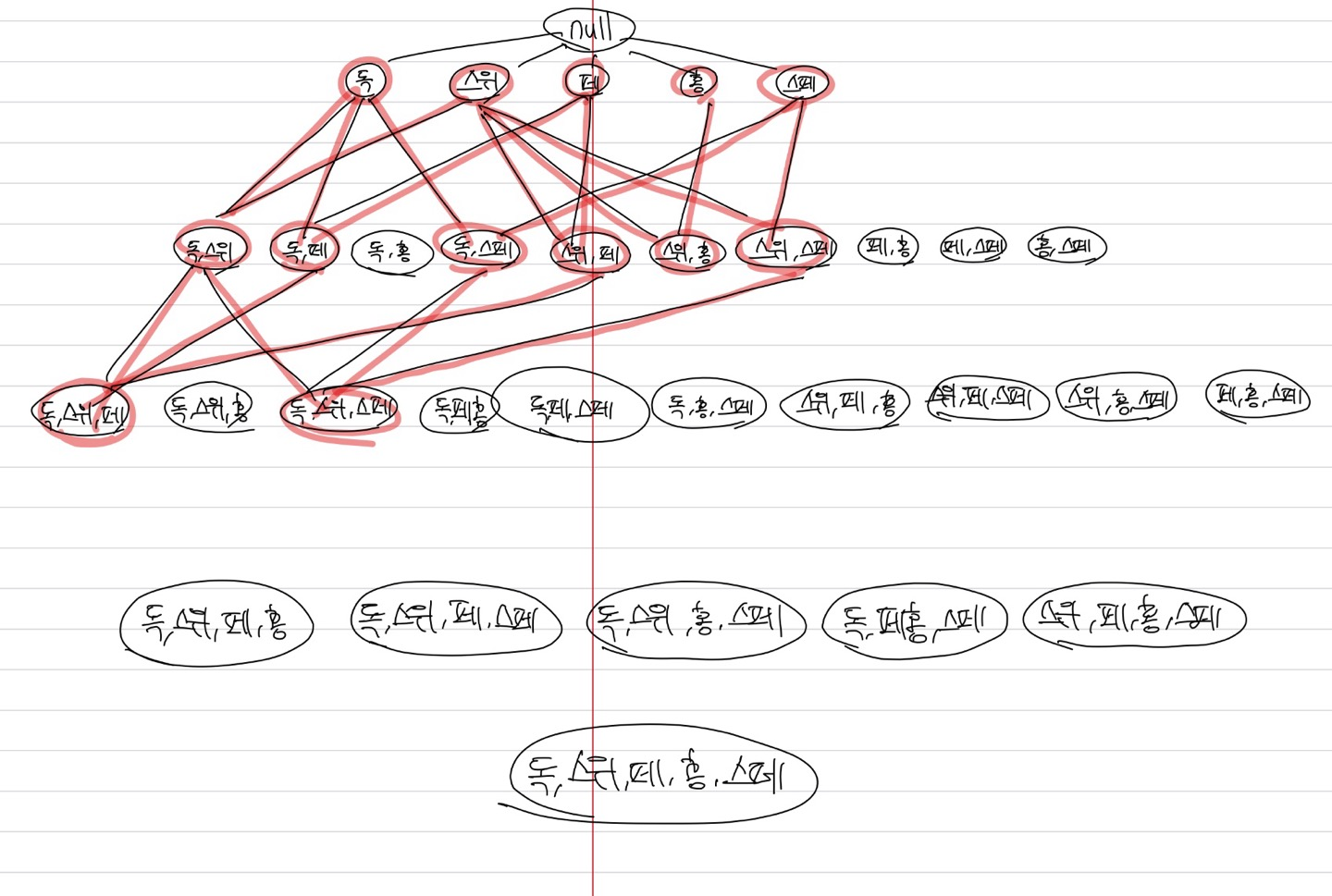
상위 집합에서 사용자가 정한 최소 지지도를 넘지 못하면 자동적으로 하위 집합은 모두 한꺼번에 제거되기에 계산량이 줄어든다.
import mlxtend
import numpy as np
import pandas as pd
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
import time
data = [
['독일','스위스','스페인'],
['스위스','홍콩'],
['스위스','페로 제도'],
['독일','스위스','홍콩'],
['독일','페로 제도'],
['스위스','페로 제도'],
['독일','페로 제도'],
['독일','스위스','페로 제도', '스페인'],
['독일','스위스','페로 제도']
]
arr = np.array(data, dtype=object)
start = time.time()
te = TransactionEncoder()
te_ary = te.fit(data).transform(data)
df = pd.DataFrame(te_ary, columns=te.columns_)
min_support_per = 0.3
min_trust_per =0.3
result = apriori(df,min_support=min_support_per, use_colnames=True)
result_chart = association_rules(result, metric="confidence", min_threshold=min_trust_per)
print(result_chart)