
[SQL] Multiset Operations, 중첩 질의문, 집합 연산, NULL JOIN
Multiset 표현
Multiset은 왼쪽과 같이 존재하지만 너무 길기 때문에 X의 개수를 세는 함수를 통해 오른쪽과 같이 간략하게 표기함

Multiset Operations
Intersection
$$ \lambda (Z) = min(\lambda(X), \ \lambda(Y)) $$
교집합을 의미하고 기호로는 $ \cap $로 표기한다.
Union
$$ \lambda (Z) = \lambda(X)+ \lambda(Y) $$
합집합을 의미하고 기호로는 $ \cup $로 표기한다.
위와 같은 Intersection, Union은 SQL Multiset Operations으로 사용된다.
Explicit Set Operators
집합 연산자를 사용하여 명시적으로 구현할 수 있다. (집합 연산자 없이도 집합을 구현할 수 있음)
INTERSECT
두 집합(table)의 교집합을 구하는 연산자이다.
$$ \begin{Bmatrix}
{R.A | R.A = S.A}
\end{Bmatrix}
\cap
\begin{Bmatrix}
{R.A | R.A = T.A}
\end{Bmatrix} $$
SELECT R.A
FROM R, S
WHERE R.A=S.A
INTERSECT
SELECT R.A
FROM R, T
WHERE R.A=T.AUNION
두 집합(table)의 합집합을 구하는 연산자이다.
$$ \begin{Bmatrix}
{R.A | R.A = S.A}
\end{Bmatrix}
\cup
\begin{Bmatrix}
{R.A | R.A = T.A}
\end{Bmatrix} $$
SELECT R.A
FROM R, S
WHERE R.A=S.A
UNION
SELECT R.A
FROM R, T
WHERE R.A=T.AUNION ALL
UNION은 집합(set) 연산자이기 때문에 중복허용이 되지 않아 Multiset연산을 할 수 없다. 합집합을 하면서 중복 허용을 하고 싶을 때는 UNION ALL을 사용한다.
SELECT R.A
FROM R, S
WHERE R.A=S.A
UNION ALL
SELECT R.A
FROM R, T
WHERE R.A=T.A
DOCTOR TABEL
| 루피 | DR20090029 | LC00010001 | 2009-03-01 | CS | 01085482011 |
| 패티 | DR20090001 | LC00010901 | 2009-07-01 | CS | 01085220122 |
| 뽀로로 | DR20170123 | LC00091201 | 2017-03-01 | GS | 01034969210 |
| 티거 | DR20100011 | LC00011201 | 2010-03-01 | NP | 01034229818 |
| 품바 | DR20090231 | LC00011302 | 2015-11-01 | OS | 01049840278 |
| 티몬 | DR20090112 | LC00011162 | 2010-03-01 | FM | 01094622190 |
| 니모 | DR20200012 | LC00911162 | 2020-03-01 | CS | 01089483921 |
| 오로라 | DR20100031 | LC00010327 | 2010-11-01 | OS | 01098428957 |
| 자스민 | DR20100032 | LC00010192 | 2010-03-01 | GS | 01023981922 |
| 벨 | DR20100039 | LC00010562 | 2010-07-01 | GS | 01058390758 |
UNION 실행 결과
UNION ALL 실행 결과
EXCEPT
$$ \begin{Bmatrix}
{R.A | R.A = S.A}
\end{Bmatrix}
/
\begin{Bmatrix}
{R.A | R.A = T.A}
\end{Bmatrix} $$
집합의 차집합 연산자로 중복이 자동으로 삭제되어 Multiset을 구현할 수 없다.
SELECT R.A
FROM R, S
WHERE R.A=S.A
EXCEPT
SELECT R.A
FROM R, T
WHERE R.A=T.AINTERSECT는 아직 Subtle problems이 존재한다. gizmos를 만들고 US와 China에 회사가 있는 본사를 구하시오 라는 문제가 있을 때 INTERSECT를 사용하면 China, US 각 국가에 하나씩만 있어도 검색이 된다.
SELECT hq_city
FROM Company, Product
WHERE maker = name
AND factory_loc = ‘US’
INTERSECT
SELECT hq_city
FROM Company, Product
WHERE maker = name
AND factory_loc = ‘China’| C.name | C.hq_city | P.pname | P.maker | P.factory_loc |
| X Co. | Seattle | X | X Co. | U.S. |
| Y Inc. | Seattle | X | Y Inc | China |
이는 P.factory_loc이 U.S. 일 때 headquarters와 P.factory_loc이 China일 때 headquarters가 같기 때문에 이런 현상이 발생한다.
이러한 문제를 해결하기 위해 DB에서는 Nested Queries를 사용한다.
Nested Queries
중접 질의문으로 FORM, WHRER절에 부속 질의문이 있는 경우 사용한다. 중첩 질의문은 위의 INTERSECT문제를 해결할 수 있고 비교연산자를 사용하여 표현한다.
Company(name, hq_city)
Product(pname, maker, factory_loc)
SELECT DISTINCT hq_city
FROM Company, Product
WHERE maker = name
AND name IN (
SELECT maker
FROM Product
WHERE factory_loc = ‘US’)
AND name IN (
SELECT maker
FROM Product
WHERE factory_loc = ‘China’)Nested Quries를 통해서 SQL이 구성적(Compositional)인 언어이며 간단한 질의문을 구성하고 조합하는 방식으로 복잡하고 정교한 질의문을 만들 수 있다는 것을 알 수 있다.
Nested Quries는 Relations을 반환한다는 것을 알아야한다.
SFW 구현
nested Queries
SELECT c.city
FROM Company c
WHERE c.name IN (
SELECT pr.maker
FROM Purchase p, Product pr
WHERE pr.name = p.product
AND p.buyer = ‘Joe Blow‘)SFW 구현
SELECT c.city
FROM Company c,
Product pr,
Purchase p
WHERE c.name = pr.maker
AND pr.name = p.product
AND p.buyer = ‘Joe Blow’Nested Queries를 IN없이도 구현할 수 있지만 FORM의 3개의 table을 Join 하는 과정에서 성능이 저하된다.
Operations
Nested Queries에서는 집합 비교 연산자를 사용할 수 있고 IN, NOT IN, ALL, ANY, EXISTS가 있다.
- IN 집합: 집합에 원소가 있을 경우 참이다.
- 원소 NOT IN 집힙: 집합에 원소가 없을 경우 참이다.
- 원소* < ALL 집합: 집합의 모든 원소가 원소*보다 클 경우 참이다.
- 원소* < ANY 집합: 집합의 원소 중에 원소*보다 큰게 하나라도 있을 경우 참이다.
- EXISTS 집합: 집합에 원소가 하나라도 존재할 경우 참이다.
- NO EXISTS 집합: 집합에 원소가 없을 경우 참이다.
ANY와 ALL은 모든 SQL에서 사용가능하지 않다.
Correlated Queries
일반적인 서브쿼리는 sub query의 결과를 main query가 이용하는 방법을 사용하나 Correlated Query는 sub query가 main query 값을 이용하고, 구해진 sub query를 main query가 이용한다.
제목이 2개 이상 존재하지 않는 영화 찾기
Movie(title, year, director, length)
SELECT DISTINCT title
FROM Movie AS m
WHERE year <> ANY(
SELECT year
FROM Movie
WHERE title = m.title)집합(Aggregation)
SQL에서 Aggregation Operations은 SUM, COUNT, MIN, MAX, AVG가 있으며 COUNT를 제외한 나머지 연산자는 single attribute에 사용할 수 있다.
COUNT
count는 중복을 어용하기 때문에 중복을 제거하기 위해서는 DISTINCT를 따로 적어야 한다.
SELECT COUNT(category)
FROM Product
WHERE year > 1995
SELECT COUNT(DISTINCT category)
FROM Product
WHERE year > 1995GROUP BY
유형별로 개수를 알고 싶을 때 GROUP BY를 사용하며 GROUP 결과에 조건을 거는 HAVING과 함께 사용하며 순서는 아래와 같다.

| S | F | W | G | H |
| 5 | 1 | 2 | 3 | 4 |
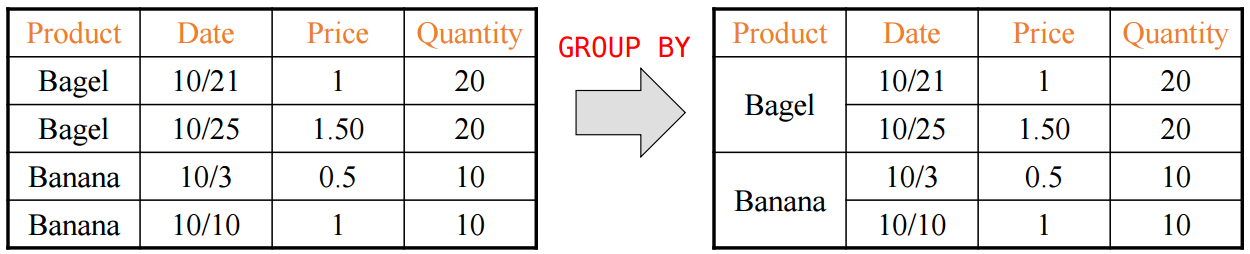
SUM 연산을 한다면 아래와 같이 적용된다.

NULL
NULL은 값을 가지고 있지 않다라고 쓰이지만 SQL에서는 값이 미정이라는 뜻이다. 그러므로 NULL을 계산하면 계산 값도 NULL이 된다.
$$ if \ x = NULL \ then \ 3-x\ is \ still \ NULL $$
SQL은 Boolean 값으로 0, 1, 0.5 3개의 값을 가진다.
- False = 0
- UNKNOWN = 0.5
- TRUE = 1
출력
NULL은 값이 미정이기 때문에 기본적으로 출력이 되지 않는다. 아래와 같은 Query문은 모든 사람을 포함하지 않을 수 있다.
SELECT *
FROM Person
WHERE age < 25 OR age >= 25NULL을 포함하여 모든 값이 알고 싶다면 IS NULL을 추가하면 된다.
SELECT *
FROM Person
WHERE age < 25 OR age >= 25
OR age IS NULLJOIN
우리가 기본적으로 사용하는 JOIN은 Inner JOIN으로 NULL값을 포함하지 않고 JOIN을 한다. NULL을 포함하고 싶다면 Left Outer join, Right Outer join, Full Outer join 등을 사용한다.
Inner Joins
Product(name, category)
Purchase(prodName, store)SELECT Product.name, Purchase.store
FROM Product, Purchase
WHERE Product.name = Purchase.prodNameSELECT Product.name, Purchase.store
FROM Product
JOIN Purchase ON Product.name = Purchase.prodName위 아래는 같은 결과가 나오는 Query이고 Inner Join으로 NULL값이 나오지 않는다.
Left Outer Join
Outer Join은 NULL값을 포함한다는 뜻이다. Left Outer Join은 오른쪽에 NULL값이 있어도 출력한다는 뜻이다.

SELECT Product.name, Purchase.store
FROM Product
LEFT OUTER JOIN Purchase ON
Product.name = Purchase.prodNameRight Outer Join
Left Outer Join의 반대로 왼쪽 table에 NULL을 포함한다는 뜻이다.
Full Outer Join
왼쪽 오른쪽 둘다 NULL을 포함한다는 뜻이다.