
[GAN] Simple 1010 pattern
1010 pattern Generator, Discriminator 구현
GAN 이미지 생성전에 간단한 pattern을 학습해 보자!

모델의 큰 그림은 이렇게 된다.
import torch
import torch.nn as nn
from tqdm import tqdm
import pandas
import matplotlib.pyplot as plt
import random
import numpy실습을 시작하기에 앞서 필요한 라이브러리를 import 해준다.
DATA
Real
def generate_real():
#real_data = torch.FloatTensor([1, 0, 1, 0]) 이것이 실제 값이지만 실제로 이런 값은 없기에 아래의 식을 사용함
real_data = torch.FloatTensor([
random.uniform(0.9, 1.0),
random.uniform(0.0, 0.1),
random.uniform(0.9, 1.0),
random.uniform(0.0, 0.1)
])
return real_dataReal Data를 생성하는 함수로 Real world에서는 1과 0으로 딱 떨어지지 않기 때문에
random.uniform(0.9, 1.0) 0.9 ~ 1.0 사이의 값
random.uniform(0.0, 0.1) 0.0 ~ 0.1 사이의 값
을 사용하여 Data를 만든다.
Fake
def generate_random(size):
random_data = torch.rand(size) # 0과 1 사이의 값을 가진 값을 size 개 반환
return random_dataFake Data를 생성하는 함수
torch.rand(size) 0~1 사이의 값을 가지는 난수를 size 만큼 생성
Discriminator Network
class Discriminator(nn.Module):
def __init__(self):
# 부모클래스 초기화
super().__init__()
# 신경망 Layer
self.model = nn.Sequential(
nn.Linear(4, 3),
nn.Sigmoid(),
nn.Linear(3, 1),
nn.Sigmoid()
)
# 손실 함수 MSE, GAN은 BCELoss를 자주씀
self.loss_function = nn.MSELoss()
#SGD 옵티마이저 설정 Adam을 주로 씀
self.optimiser = torch.optim.SGD(self.parameters(), lr = 0.01)
#진행 측정을 위한 변수 초기와
self.counter = 0
self.progress = []
pass
#모델 실행
def forward(self, inputs):
return self.model(inputs)
#모델 학습
def train(self, inputs, targets):
outputs = self.forward(inputs)
loss = self.loss_function(outputs, targets)
# 10 마다 loss 저장
self.counter += 1
if (self.counter % 10 == 0):
self.progress.append(loss.item())
pass
if (self.counter % 10000 == 0):
print("counter = ", self.counter)
pass
# 기울기 초기화 후 역전파
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
pass
# loss 시각화
def plot_progress(self):
df = pandas.DataFrame(self.progress, columns=['loss'])
df.plot(ylim=(0, 1.0),
figsize=(16, 8),
alpha=0.1,
marker='.',
grid = True,
yticks = (0, 0.25, 0.5)
)
pass
passnn.Module을 상속받아 신경망 class를 만든다.
검증
D = Discriminator()
for i in range(10000):
# Real data
D.train(generate_real(), torch.FloatTensor([1.0]))
#Fake data
D.train(generate_random(4), torch.FloatTensor([0.0]))
passloss가 전체적으로 줄어든 것처럼 보이지만 중간중간 높은 값을 보임
Real Data와 Fake Data의 학습차이 때문인지 확인하기 위해 loss 값을 따로 구함

Real 값의 loss값은 안정적으로 떨어지지만 Fake의 loss값을 그렇지 않은 걸 확인할 수 있다.
Fake 데이터를 0이라고 예측해야 하는데 쉽지 않은가 보다

모델 학습 결과 1010 패턴이 들어가면 1.0에 가까운 값을 그렇지 않으면 0.0에 가까운 결괏값이 나옴
Discriminator의 학습이 괜찮게 됐다는 것을 알 수 있다
Generator Network
Generator 생성
Generator는 Discriminator를 속이기 위한 데이터를 만들어낸다.
즉 마지막 출력 layer는 실제 데이터와 일치하도록 4개의 node가 필요하다.
그렇다면 은닉, 입력 layer의 크기는 어떻게 지정해야 할까?
훈련을 위해서는 충분히 큰 게 좋지만 훈련 시간을 고려하여 결정해야 한다.
Generator와 Discriminator는 경쟁적 학습을 하기에 비슷한 속도로 학습이 되어야 하기에 많은 사람들이 Discriminator와 Generator의 크기를 같게 한다
Discriminator가 4 -> 3 -> 1이었기에
Generator는 1 -> 3 -> 4로 해준다
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(1, 3),
nn.Sigmoid(),
nn.Linear(3, 4),
nn.Sigmoid()
)
self.optimiser = torch.optim.SGD(self.parameters(), lr=0.01)
self.counter = 0
self.progress = []
pass
def forward(self, inputs):
return self.model(inputs)
def train(self, D, inputs, targets):
g_output = self.forward(inputs)
d_output = D.forward(g_output)
loss = D.loss_function(d_output, targets)
self.counter += 1
if (self.counter % 10 == 0):
self.progress.append(loss.item())
pass
self.optimiser.zero_grad()
loss.backward()
self.optimiser.step()
pass
# loss 시각화
def plot_progress(self):
df = pandas.DataFrame(self.progress, columns=['loss'])
df.plot(ylim=(0, 1.0),
figsize=(16, 8),
alpha=0.1,
marker='.',
grid = True,
yticks = (0, 0.25, 0.5)
)
pass
passDiscriminator와 다르게 loss_function이 없다. 필요 없기 때문인데 그 이유는 판별기로 흘러온 loss를 통해 가중치를 업데이트하기 때문이다.
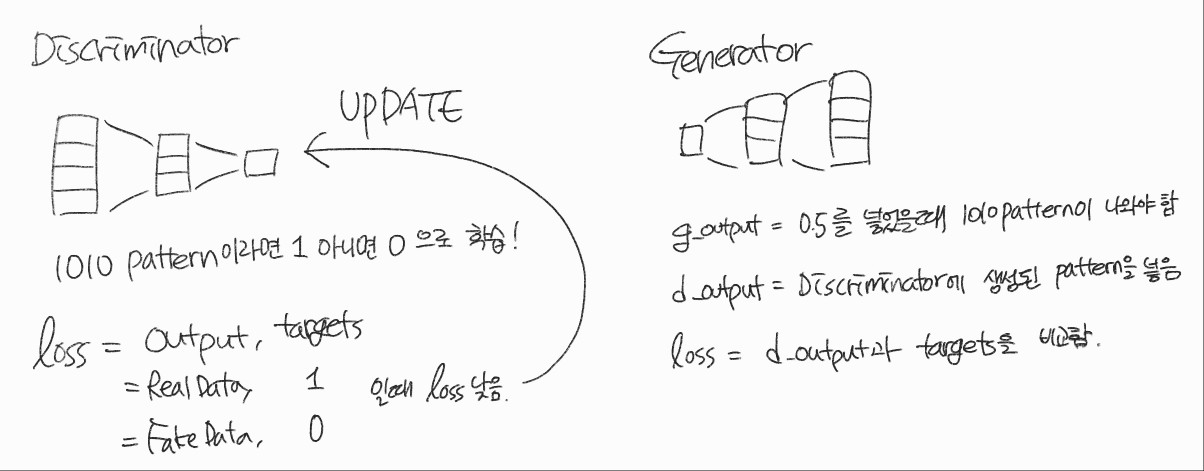

0.5를 넣고 랜덤 한 4개의 수를 얻음
Train
D = Discriminator()
G = Generator()
image_list = []
for i in tqdm(range(10000)):
# 참에 대한 판별기 훈련
D.train(generate_real(), torch.FloatTensor([1.0]))
# 거짓에 대한 판별기 훈련
# G의 기울기는 계산되면 안되기 때문에 detach 사용
D.train(G.forward(torch.FloatTensor([0.5])).detach(), torch.FloatTensor([0.0]))
# 생성기 훈련
G.train(D, torch.FloatTensor([0.5]), torch.FloatTensor([1.0]))
if (i%1000 == 0):
image_list.append(G.forward(torch.FloatTensor([0.5])).detach().numpy())
이전에는 loss가 0을 향해 떨어졌지만 0,35 근처를 맴도는 것을 확인할 수 있다
왜 이런 현상이 발생했을까?
Discriminator가 real data인지 fake data인지 구별하지 못하기에 0.5를 결괏값으로 주고 loss로 MSE를 사용했기 때문에 0.25가 나오게 된다.



훈련하면 할수록 1010 pattern이 잘 보임