[GAN] GANs Generative Adversarial Networks
GANs Generative Adverial Networks
- 기존의 VAE는 L2loss (픽셀별로 값들이 근접해야 함) 로 인해 blurry한 이미지가 나오는 문제가 있고 복잡하고 고차원인 학습 분포로부터 데이터를 샘플링하는 것이 불가능하기 때문에 Gan이 탄생하였다
Generative를 위해 Neural Network를 이용하여 Random noise를 입력으로 주어 Output을 뽑아낸다.
문제 -> 각 샘플이 어떤 학습 이미지로 매핑되느지 알 수 없음(복원 불가능)
해결책 -> Discriminator network를 이용하여 생성된 이미지가 분포 내에 속하는지 판단함
즉, DIscriminator network 와 Generator network를 이용하여 학습한다 (Two - player game)
이는 경찰과 위조지폐범 사이의 게임에 비유되고 경찰 = Discriminator, 도둑 = Generator network 이다.
위조지폐범은 진짜 같은 화폐를 만들도록 노력하고 경찰은 진짜 같은 위조 지폐를 판별하기 위해 노력한다.
이 과정에서 DIscriminator와 Generator는 적대적으로 학습한다
목적 함수
$$ max_{G}min_{D} L(D,G) = E_{x~Pdata(x}[-logD(x)] + E_{z~p_{z}(z)}[-log(1-D(G(z)))] $$
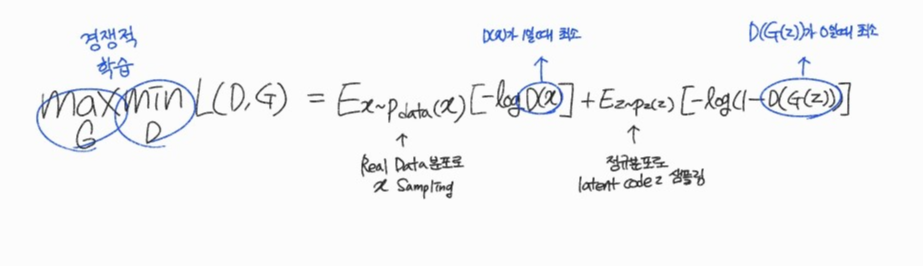
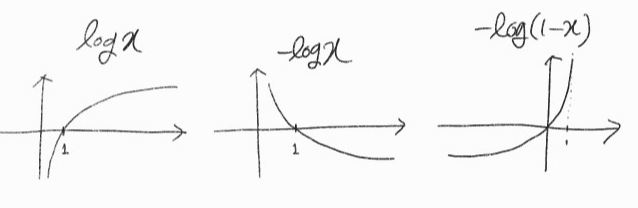
- G는 L(D,G)를 최대화해야 함 \( E_{z~p_{z}(z)}[-log(1-D(G(z)))] \)에만 영향을 끼침
- D는 L(D,G)를 최소화해야 함
즉, D(x)는 1로 (Real data는 1로) D(G(z)) 는 0으로 (Fake data는 0으로) 예측해야함
예시
$$ max_{x}min_{y} f(x,y) = x^{2} + 2xy - 3y^{2} + 4x + 5y + 6 $$
- 랜덤으로 x, y의 초기값 설정함
- \( f(y = -0.5) = x^{2} - x - 0.75 + 4x - 2.5 + 6 = x^{2} + 3x + 2.75 \)
- \( f(x = -1 ) = 1 -2y - 3y^{2} -4 +5y + 6 = -3y^{2} + 3y + 3 \)
- 각각 x에 대해 y에 대해 편미분하여 gradient descent를 수행한다
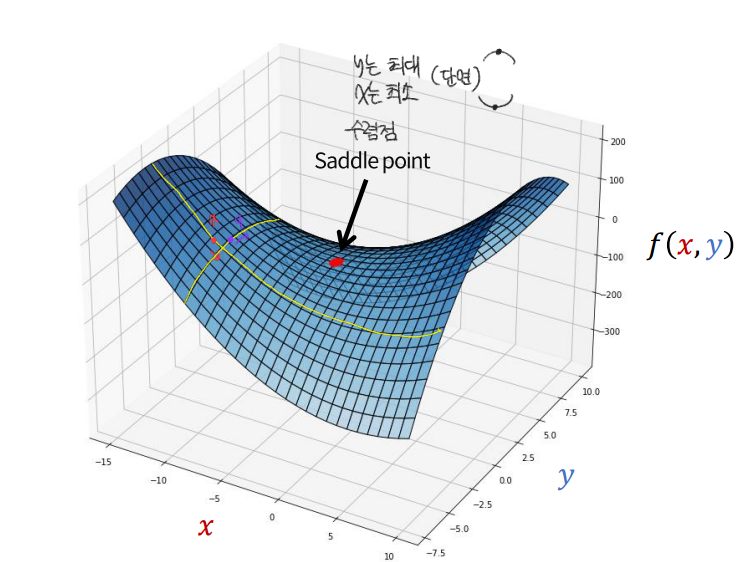
학습
Gradient Desent on discriminator
\(min_{D} L(D,G) = E_{x~Pdata(x}[-logD(x)] + E_{z~p_{z}(z)}[-log(1-D(G(z)))] \)
Gradient ascent on generator
\( max_{G} L(D,G) = E_{z~p_{z}(z)}[-log(1-D(G(z)))] \)
\( max_{G} L(D,G) = E_{z~p_{z}(z)}[-log(D(G(z)] \) <- 이거 사용함
번갈아가며 UPDATE하지만 일반적으로 Generator의 학습이 시간이 많이 들고 어렵기 때문에 초반에는 성능이 좋지 못함
> 그렇기 때문에 변형 함수를 사용함, Fake data에 대한 gradient가 커짐
\( max_{G} L(D,G) = E_{z~p_{z}(z)}[-log(D(G(z)] \)
Basic 코드
import torch
import torch.nn as nn
#Discriminator 구조
D = nn.Sequential(
nn.Linear(783, 128),
nn.LeakyReLU(),
nn.Linear(128, 784),
nn.Sigmoid())
#Generator 구조
G = nn.Sequential(
nn.Linear(100, 128),
nn.LeakyReLU(),
nn.Linear(128, 784),
nn.Tanh())
#BCELoss
criterion = nn.BCELoss()
d_opti = torch.optim.Adam(D.parameters(), lr = 0.01)
g_opti = torch.optim.Adam(G.parameters(), lr = 0.01)
while True:
# train D
loss = criterion(D(x), 1) + criterion(D(G(z)), 0)
loss.backward()
d_opti.step()
#train G
loss = criterion(D(G(z)), 1)
loss.backward()
d_opti.step()