Machine Learning/이론
머신러닝 Machine Learning Bias, Variance
파송송
2022. 8. 17. 16:37
728x90
수정이 있어 수식의 변수명이 맞지 않음 -> \( f(x) \) 는 \( \hat{f}(x)^{*} \) 와 같이 기댓값은 변수 위에 -로 표시함
Bias, Variance
- 모델에 의한 오류는 크게 Bias와 Variance로 구분된다.
- Bias(편향)
- 평균적으로 모델이 얼마나 정확하게 추정이 가능한지에 대한 측정 지표
- Variance(분산)
- 모델 학습 시 개별 추정이 얼마나 크게 차이나는지에 대한 측정 지표

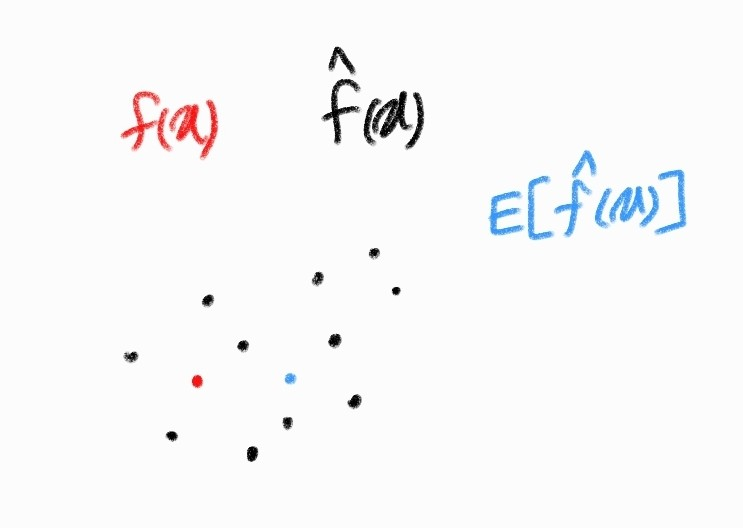
\( \hat{f}(x)^{*} \) : 입력 데이터 \( x \)에 대한 실제 정담
\( \hat{f}(x) \) : 입력 데이터 \( x \)에 대한 예측값
\( E[\hat{f}(x)] \) : \( \hat{f}(x) \)의 평균 -> 대표 예측값
Bias
- 모델을 통해 얻은 예측값과 실제값과의 차이의 평균 -> 예측값이 실제값과 얼마나 떨어져 있는 지를 나타냄
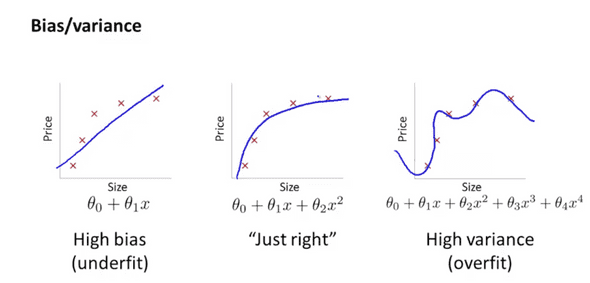
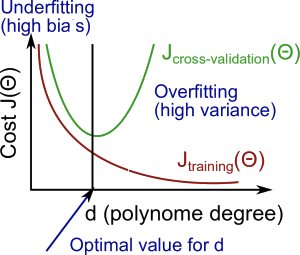
- High Bias = 과소적합 Underfitting
$$ Bias [\hat{f}(x)] = E[\hat{f}(x) - f(x)] $$
Variance
- 다양한 데이터 셋에 대하여 예측값이 얼만큼 변화할 수 있는지에 대한 양의 개념
- 예측값이 퍼져있는 정도
- High Variance = 과적합 Overfitting
$$ Var[^f(x)]=E[(^f(x)−E[^f(x)])^{2}]=E[^f(x)^{2}]−E[^f(x)]^{2} $$
평균과 변량의 편차를 제곱하여 나타낸 것
Bias, Variance 관계
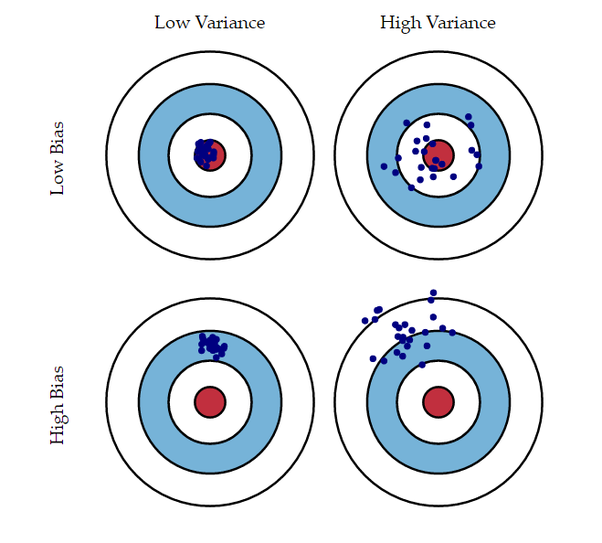
왼쪽 위, 오른쪽 위, 왼쪽 아래, 오른쪽 아래로 하여 1번부터 4번까지 번호를 부여하면 아래와 같이 설명할 수 있다.
- Low Bias and Low Variance
- bias가 낮기 때문에 예측값과 정답값의 오차가 작고 variance가 낮기 때문에 예측값들의 분포가 작다. Optimal model
- Low Bias and High Variance
- bias가 낮기 때문에 예측값과 정답값의 오차가 작다, variance가 높기 때문에 예측값의 분포가 크다. Overfitting에 속하며 주로 높은 복잡도를 가진 모델에 많이 생기는 문제이다.
- High Bias and Low Variance
- bias가 높기 때문에 예측값과 정답값의 오차가 크고, variance가 낮기 때문에 예측값의 분포가 작다. Underfitting에 속하며 주로 낮은 복잡도를 가진 모델에 많이 생기는 문제이다.
- High Bias ans High Variance
- bias가 높기 때문에 예측값과 정답값의 오차가 크고 variance가 높기 때문에 예측값의 분포가 크다
- 망한 모델
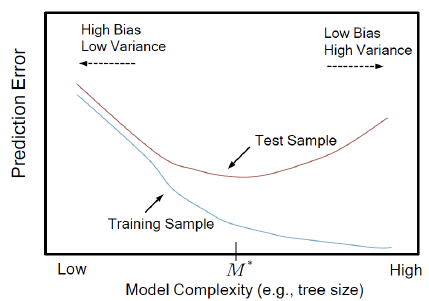
Trade off
Bias와 Variance는 Trade off 관계이기 때문에 둘다 낮아지는 최적의 해를 찾아야 한다.
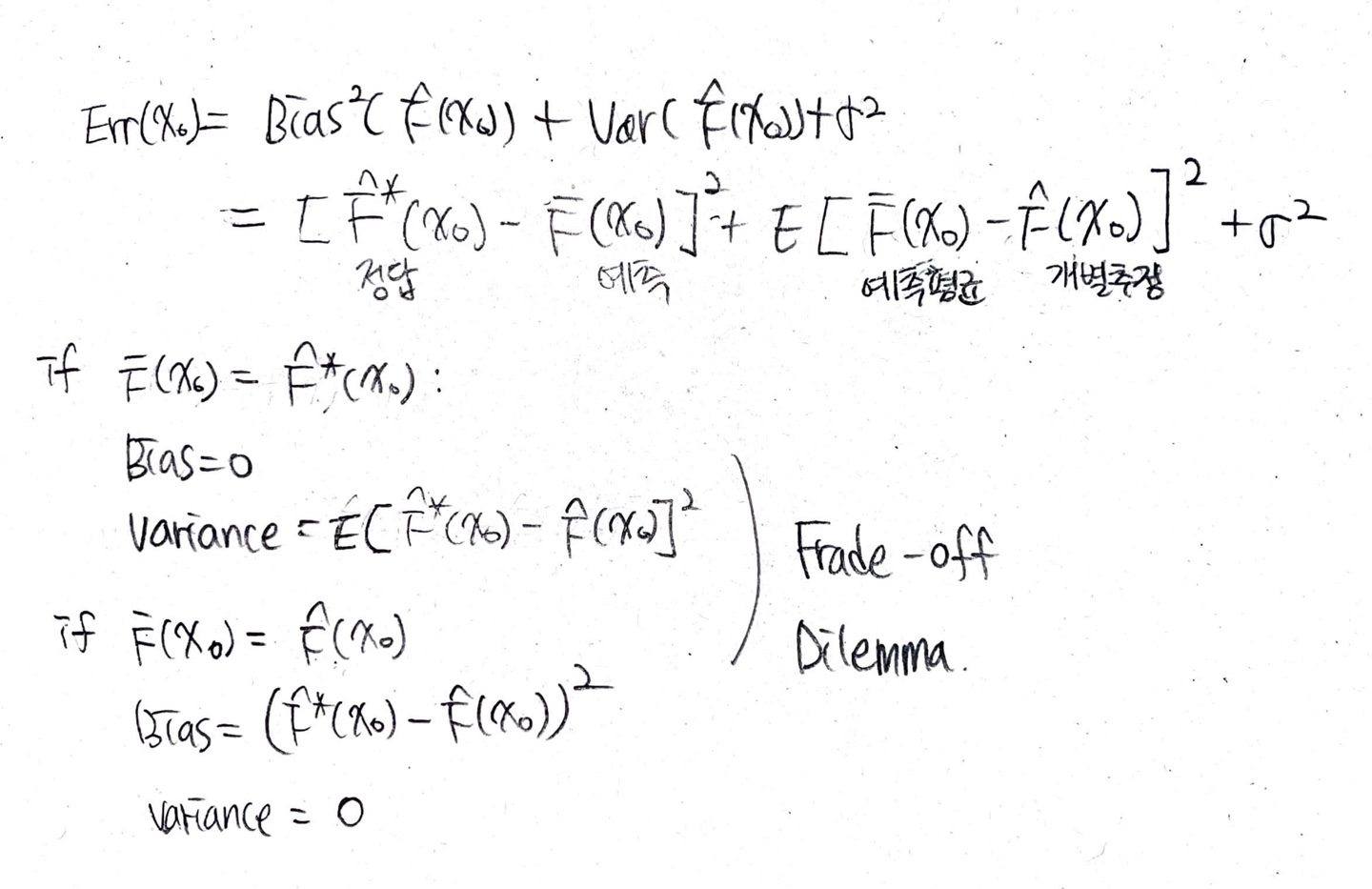

추정 예시
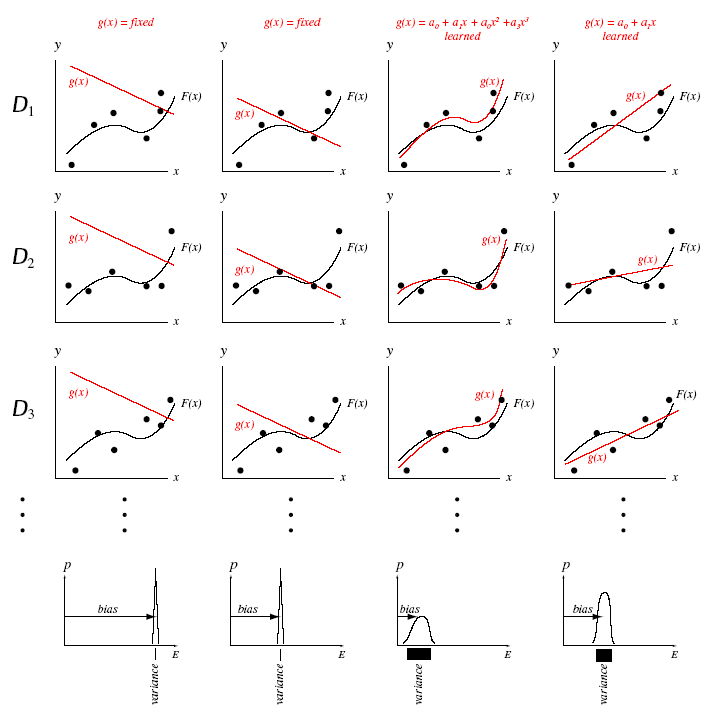
왼쪽부터 1~4번을 부여한다고 하면 아래와 같이 해석이 가능하다.
- 1번과 2번은 고정된 g를 가지며 dataset에 따라 함수식이 변하지 않아(가중치 학습이 없음) variance(변화량)이 0이 된다.
- 2번이 운좋게 1번보다 error가 적은 직선이 그어졌기 때문에 2번이 1번보다 bias가 낮다.
- 3번은 3차 다항식을 가지고 dataset에 가장 fit 하게 학습되기 때문에 bias가 작고 dataset에 따라 함수식에 큰 변동이 있기 때문에 높은 variance를 가진다.
- 4번은 1차 다항식으로 2번보다는 적은 bias를 가지나 1차식으로 함수이기 때문에 변동량이 적어 3번보다 적은 Variance를 가진다.
728x90