
728x90
https://arxiv.org/pdf/2205.11487v1.pdf
Abstract
- Imagen: a text to image diffusion 모델로 높은 수준의 language understanding과 photorealism을 가짐
- large transformer language models를 통해 text를 이해하고 이를 기반으로 diffusion model이 고화질 이미지를 생성함
- T5와 같은 generic pre-trained large language models로 text를 encoding 하는 것은 image synthesis에 효과적이라는 것을 이 논문에서 밝혀냄 -> LM의 크기를 늘리는 것이 Diffusion 모델의 크기를 늘리는 것보다 성능이 좋게 나옴
- 벤치마크(어떤 것의 성능을 시험하여 수치화 가는 것) DrawBench를 통해 평가를 진행하였고 Imagen의 선호도가 높다는 것을 발견함
Introduction
- Multimodal은 text to image synthesis에서 두각을 나타내고 있으며 창의적인 이미지 생성 및 편집 applications 쪽에서 관심을 받고 있음
- 수요에 맞는 고퀄리티 공급을 위해 transformer language models과 cascaded diffusion models를 합성한 Imagen 연구
- text-image data만 사용하는 이전 연구 Zero-Shot Text-to-Image Generation 등과 달리 text embeddings from large LMs을 활용하면 더욱 효과적인 text to image synthesis을 할 수 있음
- Imagen은 embedding 매핑을 위한 frozen T5-XXL encoder + super-resolution diffusion model로 구성되어 있음
- diffusion model은 text embedding sequence에 따라 조정되며 classifier-free guidance를 사용함

- DrawBench: text prompts for text to image evaluation
- DrawBench는 다양한 의미 특성을 조사하도록 설계된 text prompts를 통해 모델을 평가함
Key contributions
- large frozen language models의 text encoder는 text to image synthesis에 효과적이라는 것을 발견함 -> LMs의 크기를 조정하는 것이 difusion model 크기를 조정하는 것보다 효과가 좋음
- high guidance weights을 활용하여 사실적인 이미지 생성을 위한 diffusion technique=(dynamic thresholding)을 도입함
- memory efficient가 좋은 Efficient U-Net을 제안함
- 7.27이라는 COCO FID(SOTA)를 달성함
- 새로운 벤치마크인 DrawBench 소개
Imagen
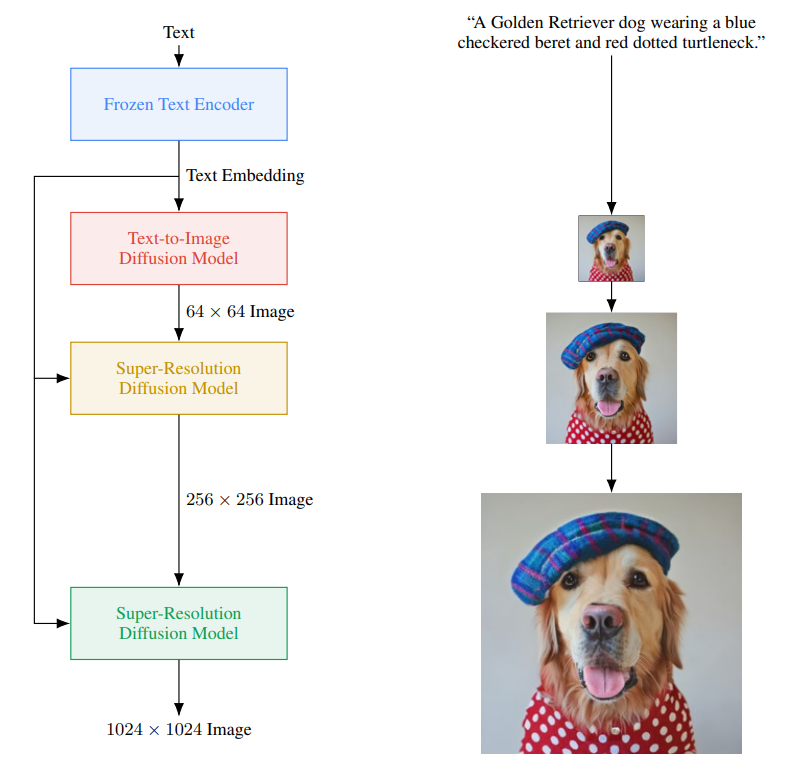
- Imagen: sequence of embedding 매핑 + cascase of conditional diffusion
1. Pretrained text encoders
- text to image models은 complexity와 compositionality를 포착하기 위한 semantic text encoder가 필요함
- text encoder는 paired image-text data로 pretrain 된 것을 표준으로 사용하고 처음부터 훈련하거나 다른 paired dataset(CLIP)에 대해 사전학습될 수 있음
- text encoders를 학습시키는 목표는 text encoders를 통해 시각적으로 의미 있는 표현을 encoding 할 수 있음을 보여주기 위함이고 특히 text to image 작업과 관련이 많음
- Large language models은 text encoding에 쓰일 수 있고 큰 텍스트 corpus에서 훈련된 모델이기 때문에 풍부하고 광범위한 분포를 통해 text encoding을 할 수 있음
- 따라서 본 논문에서는 text to image task를 위해 BERT, T5, CLIP와 같은 pre-trained text encoder를 사용하고 단순화를 위해 weights of these text encoders를 freeze 함
result
- text encoder 조정이 이미지 생성 품질에 영향을 끼침을 발견함
- DrawBench에서 CLIP보다 T5-XXL encoder를 더 선호한다는 것을 발견함(왜?)
2. Diffusion models and classifier-free guidance
- Diffusion models: 반복적인 denoising process를 통해 Gaussian noise를 학습된 데이터 분포의 샘플로 변환하는 생성 모델
- Diffusion model \( \hat{x}_{\theta} \) 목적함수
- \( \mathbb{E}_{x,c,\varepsilon ,t}[w_{t}||\hat{x}_{\theta}(\alpha_{t}x+\sigma _{t}\varepsilon, c)-x||^{2}_{2}] \)
- \( t \sim U([0,1]), \ \epsilon \sim N(0,I) \)
- \( (x,c) \)은 data-conditioning pairs이고 \( \alpha_{t}, \sigma_{t}, w_{t} \)는 샘플 품질에 영향을 미치는 t 함수임
- \( \hat{x}_{\theta} \) 는 \( z_{t} : = \alpha _{t}x+ \sigma _{t} \epsilon \)을 \( x \)로 denoise 하게 학습됨
- Ancestral sampler, DDIM(샘플링 방법)과 같은 샘플링은 \( noise \ z_{1} \sim N(0,I) \)에서 시작하며 \( 1=t_{1} > \ldots > t_{T}=0 \)에 대하여 점진적으로 \( z_{t1}, \ldots , z_{tT} \)을 생성함 이 값은 \( \hat{x}_{0}^{t}=\hat{x}_{0}^{\theta}(z_{t},c) \)의 함수임
- Classifier guidance는 샘플링 중 사전 학습된 모델 \( p(c|z_{t})의 기울기를 사용하여 conditional diffusion model의 다양성을 감소시키면서 품질을 개선하는 테크닉
- 학습 중 랜덤 하게 c를 drop 하여 하나의 diffusion model을 conditional 및 unconditional 목적 함수로 동시에 학습시키는 테크닉으로 수정된 \( x \) 예측값 \( (z_{t}- \sigma \tilde{\epsilon _{\theta}})/ \alpha _{t} \)를 사용함
- \( \tilde{ \epsilon_{\theta}} (z_{t},c)=w \epsilon_{\theta}(z_{t},c)+(1-w) \epsilon _{\theta}(z_{t}) \)
- \( \epsilon_{\theta}:= \frac{z_{t}- \alpha_{t}\hat{x}_{\theta}}{ \sigma_{t}} \)
- \( w \)는 guidance 가중치로 \( w = 1 \) 일 경우 gudiance 효과가 사라지고 w가 증가됨에 따라 guidance 효과가 강해짐
- Imagen은 효과적은 text conditioning을 위해 classifier-free guidance에 의존함
3. Large guidance weight samplers
guidance weight란 text와 이미지 간의 상호작용에서 텍스트의 영향력을 제어하는 가중치이다.
guidance weight가 높다면 text에 focus하여 이미지를 생성하고 낮다면 모델이 자체적으로 이미지를 생성하는 것에 집중한다.
- text-guided diffusion 연구의 결과를 확증하고 classifier-free guidance weight를 높이면 image-text alignment가 향상되지만 이미지 fidelity가 손상되는 문제 발견
- image-text alignment: image와 text간의 관계를 맞추는 능력
- 이는 높은 guidance weight로 인한 train-test 불일치 때문
- 각 sampling step t에서 \( \hat{x_{0}} \)은 학습 데이터 x와 동일한 범위 내에 있어야 하지만 높은 guidance로 인해 x의 범위를 넘게 됨
- 이를 해결하기 위해 static thresholding과 dynamic thresholfing을 제안함
Static thresholding
- static thresholding: x-prodiction을 [-1, 1]로 elementwise clipping 하는 것
- 이전 논문(Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising Diffusion Probabilistic Models. NeurIPS, 2020.)에서 사용되었으나 강조되지 않았고 guided sampling의 맥락에서 연구되지 않음
- static thresholding은 high guidance weight로 샘플링되는데 필수적이며 blank images 생성을 방지함
- 그러나 guidance weight 증가함에 따라 fidelity가 떨어지는 이미지를 생성함
Dynamic thresholding (solution)
- Dynamic thresholding: 각 샘플링 step에서 \( \hat{x}^{t}_{0} \)의 특정 백분위수 절대 픽셍 값을 설정하고 s > 1이면 \( \hat{x}^{t}_{0} \)의 범위를 [-s, s]로 threshold로 지정한 다음 s로 나눔
- 포화된 픽셀(-1, 1과 가까운 픽셀)은 안쪽으로 밀어 넣어 각 step에서 픽셀이 포화되지 않게 능동적으로 방지함
- dynamic thresholding을 사용하면 매우 큰 guidance weight를 사용할 때 image-text alignment가 좋아지며 훨씬 더 사실적인 결과를 얻을 수 있음을 발견함
4. Robust cascaded diffusion models
- Imagen은 base 64x64 모델의 파이프라인과 2개의 text conditional super-resolution diffusion model을 활용하여 64x64 -> 256x256 -> 1024x1024로 upsampling 함
- Noise conditioning augmentation 기능이 있는 cascaded diffusion model은 높은 fidelity의 이미지를 생성하는데 효과적임
- noise level conditioning을 통해 저해상도 모델에서 생성된 아티팩트를 처리할 수 있음
- Imagen은 2개의 super-resolution model에 noise conditioning augmentation을 사용하여 이것이 높은 fidelity 이미지 생성에 중요하다는 것을 발견함
- conditioning low-resolution image와 augmentation level(aug_level)(이미지 확대 수준)이 주어지면 aug_level로 저해상도 이미지를 손상시키고 diffusion model로 aug_level을 조정함
- \( aug\_level \in [0,1] \)
- 훈련 중 aug_level은 무작위로 선택되지만 inference 단계에서는 다양한 값을 sweep 하여 최상의 샘플 품질을 찾음
- 본 논문에서는 Gaussian noise를 augmentation으로 사용하고 diffusion model에서 사용하는 forward process와 유사한 variance preserving Gaussian noise augmentation을 적용함
5. Neural Nerwork Architecture
- BASE MODEL
- U-Net architecture from for our base 64 × 64 text-to-image diffusion model을 사용함
- 신경망은 pooled embedding vector로 된 text embedding을 time-step embedding에 대하여 컨디셔링 됨
- 다양한 해상도에서 text embedding을 cross attentiond에 더해 text embedding의 전체 sequence를 컨디셔링함
- 성능 개성을 위해 attention layer와 pooling layer에 text embedding을 위한 layer Normalization을 사용함
- SUPER-RESOLUTION MODEL
- 64x64 -> 256x256 super-resolution의 경우 Improved DDPM과 Palette에 사용된 U-Net model을 사용함
- 메모리 효율성, inference 속도, 수렴 속도를 위해 U-Net model에 다양한 수정을 하였고 최종 모델을 Efficient U-Net이라고 함
- 256256 ->->1024×1024 super-resolution model은 1024×1024 이미지의 64×64 -> 256×256 crop으로 학습시킴
- 이를 위해 self-attention layer를 제거하고 텍스트 cross-attention layer를 유지함
- inference 중에는 full 256×256 저해상도 이미지를 입력으로 받아 upsampling 된 1024×1024 이미지를 출력함
Evaluating Text-to-Image Models
- COCO
- text to image 평가, zero-shot 설정을 평가하기 위한 표준 벤치마크
- metrics로는 FID와 CLIP를 사용함
- FID는 지각적 품질을 잘 측정하지 못하고 CLIP은 countion에 효과적이지 못하기 때문에 추가적으로 인간 평가를 실시함
- Draw Bench
- text to image model 간의 평가 및 비교를 지원하는 포괄적이고 어려운 프롬프트 세트를 도입함
- 모델의 다양한 능력을 테스트하는 11개의 카테고리의 프롬포트를 가지고 있으며 총 200개의 프롬프트로 구성되어 크고 포괄적인 데이터셋에 대한 요구와 사람의 평가가 가능할 만큼 충분히 작은 데이터셋에도 적절한 균형을 유지함
Experiments
Results on COCO
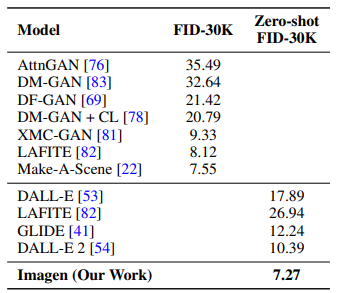
Imagen은 7.27로 SOTA Zero-shot FID를 달성하였고 DALL-E를 성능을 뛰어넘었다.
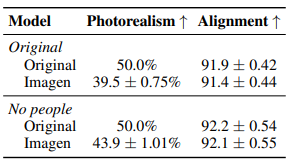
Image의 quality와 alignment에 대한 인간 평가 결과표이다.
Results on Draw Bench
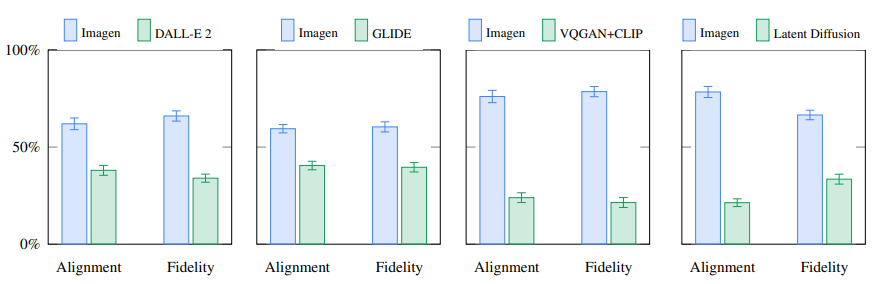
- alignment와 fidelity에 대한 human raters가 Imagen이 높음 -> Imagen이 생성한 이미지를 선호함
Analysis of Imagen
다양한 guidance값에 대한 trade-off 곡선
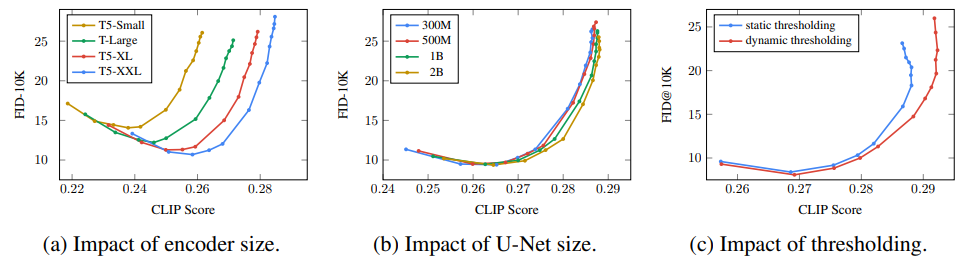
- text encoder의 크기가 커지면 image-text alignment와 fidelitu가 지속적으로 개선됨 -> U-NET의 크기를 키우는 것보다 Text encoder의 크기를 키우는 것이 개선이 더 잘됨
- Dynamic thresholding을 사용하였을 때 이미지의 품질과 alignment가 좋아지며, 특히 guidance weight가 클 때 큰 효과를 보임
Related Work
- Diffusion models은 fidelity, diversity문제없이 GANs보다 좋은 성능을 보임
- Autoregressive models, GANs, VQ VAE Transformer-based methods, diffusion models, DALL-E 2은 뛰어난 text to image 성능을 보여줌
- Imagen은 latent prior(잠재공간의 분포)를 배우지 않아도 좋은 성능을 가지기 때문에 훨씬 간단한 모델임
- GLIDE는 cascaded diffusion models을 사용하지만 LMs가 없어 image text alignment 성능이 떨어짐
- XMC-GAN은 BERT를 통해 Encoder 하지만, 본 논문을 통해 text encoder의 효과를 입증함
Conclusions, Limitations and Societal Impact
- U-NET(cascaded diffusion models)의 크기 조정보다 괜찮은 LMs를 탐색하는 향후 연구 방향을 장려함
- classifier-free guidance을 강조하며 dynamic thresholding을 도입함
- 이 연구의 목표는 Imagen을 test bed로 하여 text to image 연구를 발전시키는 것
- 사용자가 실생활에서 사용하기엔 무리가 있지만 이 연구가 potential downstream applications이 있다고 생각하며 인간의 창의성을 보완, 확대, 증대시킬 수 있는 잠재력을 가지고 있음
- 이 연구는 이미지 편집 등의 확장 프로그램으로 개발될 수 있음
- 잘못된 방식으로 쓰일 경우를 염려하여 source를 공개하지는 않을 예정임
- Datsset의 경우 입증되지 않은 대규모 웹 스크랩 데이터셋에 의존하게 되었음
- 이는 연구를 빠르게 발전하게 했지만 윤리적 문제가 존재했음
- 사회적 고정관념, 억압적인 관점 소외된 그룹에 대한 부정적인 데이터 등이 포함된 모델은 소외, 차별, 배제를 경험하고 있는 개인에게 부정적인 영향을 미칠 수 있음
- 생성 모델 연구에 대한 윤리적인 문제에 대한 내용
728x90