
SQL
SQL(Structured Query Language)은 Relational database에 정보를 저장하고 처리하기 위해 쓰이는 프로그래밍 언어로 SQL문을 사용하면 데이터베이스에서 정보를 저장, 업데이트, 제거, 검색할 수 있고 Python과 같은 high-level 언어이다.
DDL(Data Definition Language), DML(Data Manipulation Language), DCL(Data Control Language), TCL(Transaction Control Language)가 있음
| 명령어 종류 | 명령어 | 설명 |
| 데이터 조작어 DML |
SELECT(=RETRIEVE) | 데이터베이스의 데이터를 조회하거나 검색하기 위한 명령어 |
| INSERT UPDATE DELETE |
데이터베이스의 테이블에 있는 데이터를 변형하는 명령어 삽입, 수정, 삭제 |
|
| 데이터 정의어 DDL |
CREATE ALTER DROP RENAME TRUNCATE |
테이블과 같이 데이터 구조를 정의하는데 사용하는 명령어 생성, 변경, 삭제, 이름변경 |
| 데이터 제어어 DCL |
GRANT REVOKE |
데이터베이스에 접근하고 객체들을 사용할 수 있도록 권한을 주고 회수하는 명령어 |
| 트랜잭션 제어어 TCL |
COMMIT ROLLBACK SAVEPOINT |
논리적인 작업 단위를 묶어서 DML에 의해 조작된 결과를 작업단위(트랜잭션)별로 제어하는 명렁어 |
Table
Relation과 Table은 schema로 지정된 속성을 가지는 tuples의 다중집합(Multiset)이다.
Multiset
Multiset이란 중복을 허용하며 순서가 없는 자료형으로 list, set과 비교하면 쉽게 이해할 수 있다.
| 중복 | 순서 | |
| List | O | O |
| Set | X | X |
| Multiset | O | X |
용어
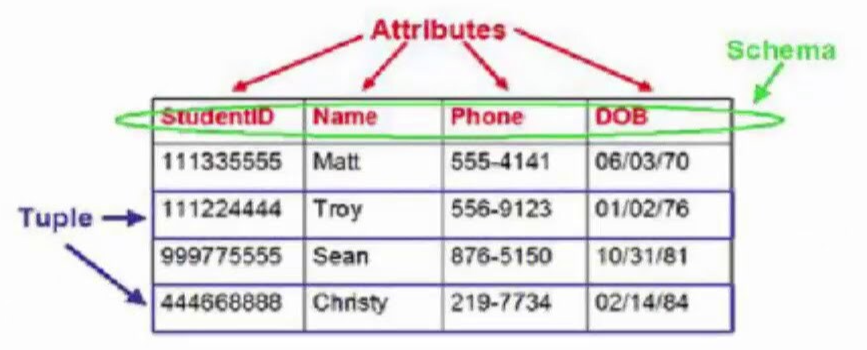
Attribute
- 속성으로 Column이라고도 불리며 각 tuple에 있는 입력된 데이터의 항목이다.
- Attribute는 Atomic을 가져야 하는데 이는 하나의 Attribute에는 하나의 정보만 들어가야 한다. 예를 들어 이름과 나이 정보를 하나의 Attribute에 적을 수 없다.
Tuple
- row, record라고도 불리며 스키마에 의해 지정된 속성을 가진 테이블의 단일 항목이다.
Cardinality
- Tuple의 수이다
Arity
- Attribute의 수이다.
모든 Attribute는 atomic type을 가져야 하며 Atomic types는 아래와 같다.
| Characters | CHAR(20), VARCHAR(50) |
| Numbers | INT, BIGINT, SMALLINT, FLOAT |
| Others | MONEY, DATETIME |
Schema
Table에서 Schema는 테이블 이름, attributes, types이다.
Product(Pname: String, Price: float, Category: String, Manufacturer: string)
Key
Attribute중 unique 한 값을 가지는 것으로 주로 밑줄이 그어져 있다. 이는 Key는 해당 table의 모든 tuple을 유일하게 구별할 수 있음을 뜻한다.
Students(sid: string, name: string, gpa: float)
sid가 key가 될 수 있으며, Key는 가능하면 있도록 설계하는 것이 좋고 이는 DBA의 몫이다. Key는 여러 개 설정할 수 있지만 이를 쌍으로 유지해야 한다.
NULL
NULL 은 '0' 없음을 뜻하고 값이 안정해진 상태를 의미한다. 하지만 Key는 모든 tuple을 유일하게 구별할 수 있어야 하기 때문에 NULL 값이 들어가면 안 되고 이는 Constrain을 통해 해결할 수 있다.
SQL Query
SELECT
가장 기본적인 Query문으로 데이터를 불러오는 역할을 하며 SFW로 외워서 사용한다.
SELECT <attributes>
FROM <one or more relations>
WHERE <conditions>
Product에서 Category가 'Gadgets'인 tuple 중모든 Attributes 정보를 가져와라

SELECT *
FROM Product
WHERE Category = 'Gadgets'
Product에서 Category가 'Gadgets'인 tuple 중 PName, Price, Manufacturer 정보를 가져와라
이때 Attribute의 정렬 순서는 SELECT에 적은 순서대로 정렬된다.
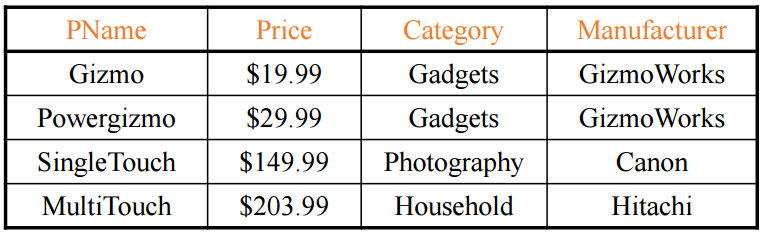
SELECT PName, Price, Manufacturer
FROM Product
WHERE Category = 'Gadgets'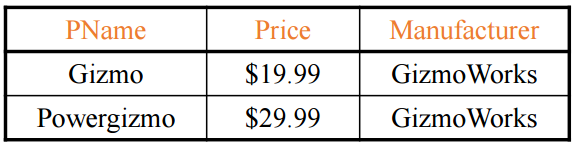
여기서 우리는 Input Schema와 Output Schema가 다르다는 것을 알아야 함
| Input Schema | Product(PName, Price, Category, Maufacturer) |
| Output Schema | Answer(PName, Price, Manfacturer) |
Output Schema는 SQL Query를 통해 나온 한정된 table이다.
변수 이름 규칙
- SQL의 명령어는 대소문자를 구분하지 않음
- SELECT = Select = select
- Product = product
- Values의 이름은 대소문자를 구분함
- Seattle \( \neq \)seattle
- 문자열은 무조건 Sigle quetes를 사용해야 한다
- 'hello' (O)
- "hello" (X)
LIKE
LIKE연산자는 문자열의 패턴을 검색하는 데 사용한다.
SELECT *
FROM Table
WHERE Att LIKE 'PATTERN'Pattern을 감지하기 위해 % 와 _를 사용한다.
- %는 몇 글자든 상관없이 모든 문자를 확인하라는 의미이다,
- _는 한 글자만 확인하라는 의미이다.
| 1. AgizmoA | 2. AAgizmoA |
2가지의 단어가 있다고 했을 때 % gizmo%는 2개의 문자열을 인식할 수 있고 _gizmo%는 1번 하나의 문자열을 인식할 수 있다.
DISTINCT
중복된 값을 Unique 하게 만드는 연산자이다.
SELECT Category
FROM Product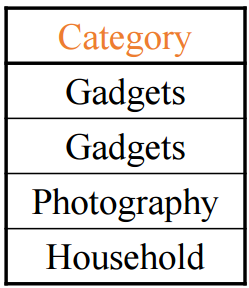
SELECT DISTINCT Category
FROM Product
ORDER BY
table의 attibute를 정렬하는 명령어이고 기본적으로 오름차순으로 되어있다.
SELECT *
FROM Table
WHERE Att1
ORDER BY Att2SELECT PName, Price
FROM Product
WHERE Category='gizmo'
ORDER BY Price, PName내림차순으로 보고 싶다면 DESC키워드를 사용하면 됨
SELECT PName, Price
FROM Product
WHERE Category='gizmo'
ORDER BY Price, PName DESCForeign Key
외래키(Foregin Key)란 두 테이블을 연결하는 데 사용하는 키이고 외래키가 포함된 테이블을 자식테이블, 외래키를 제공하는 테이블을 부모 테이블이라고 부른다.
자식테이블은 부모테이블에 의존성을 가지고 있으며 constraint를 가지고 있다.
constraint
외래키의 Att는 부모테이블에 존재하는 값으로만 지정해야 한다.

Enrolled의 student_id는 외래키로 Students의 sid에 의존성을 지닌다. 여기서 Enrolled.student_id의 값은 Students.sid에 의존하기 때문에 Students.sid에 존재하는 값으로만 지정되어야 한다.
여기서 Students의 한 학생 tuple을 지우고 싶다면 우선 의존성을 검사한 뒤 삭제한 학생 정보를 가진 student_id tuple을 다 삭제한 뒤에 sid를 삭제할 수 있고 NULL값이 있다면 자동으로 무시된다.
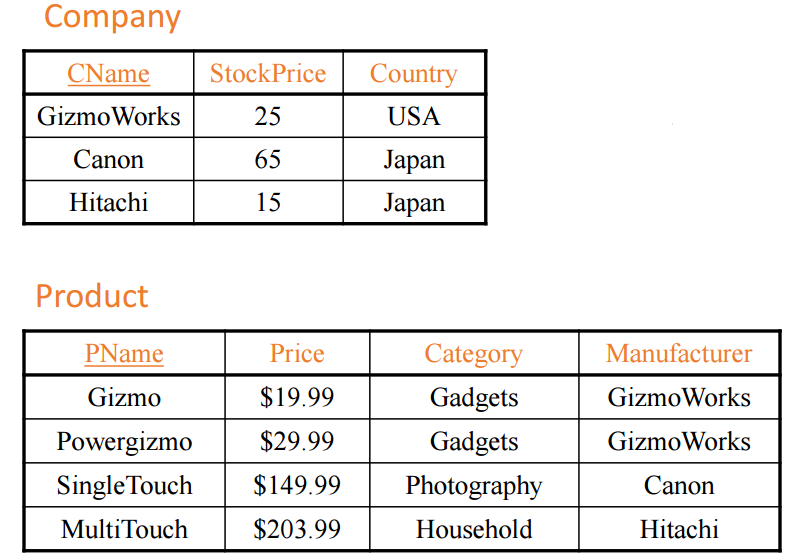
Company의 CName이 삭제된다면 Product의 Manufacturer도 자동으로 삭제된다.
선언
위의 Enrolled은 CREATE 명령문을 통해 아래와 같은 코드로 생성할 수 있다.
CREATE TABLE Enrolled(
student_id CHAR(20),
cid CHAR(20),
grade CHAR(10),
PRIMARY KEY (student_id, cid),
FOREIGN KEY (student_id) REFERENCES Students(sid)
)Joins
Joins은 두 개 이상의 테이블 사이의 관련 열을 기반으로 행을 결합하여 의미 있는 정보를 추출하는 데에 사용한다.
Product(PName, Price, Category, Manufacturer)
Company(CName, StockPrice, Country)위의 2개의 테이블이 있을 때 일본에서 생산되고 가격은 200불 이하인 제품을 찾으시오.
# 1 Join없이 구현
SELECT PName, Price
FROM Product, Company
WHERE Manufacturer = CName
AND Country=‘Japan’
AND Price <= 200# Join으로 구현
SELECT PName, Price
FROM Product
JOIN Company ON Manufacturer = Cname // Product를 기준으로 Company를 Join함
AND Country=‘Japan’
WHERE Price <= 200위의 문제는 하나의 테이블로는 해결할 수 없기에 2개의 테이블을 join 하여 문제를 해결한다.
Join은 2개의 table을 하나로 묶어줄 연결고리가 필요하고 위의 코드에서는 Manufacturer = CName가 그 역할을 한다.
Ambiguity
서로 다른 table의 Att가 같을 경우 모호성이 생기기 때문에 명시적으로 바꿔줘야 한다.
Person(name, address, worksfor)
Company(name, address)명시적 표기
SELECT DISTINCT Person.name, Person.address
FROM Person, Company
WHERE Person.worksfor = Company.name약어 표기
SELECT DISTINCT p.name, p.address
FROM Person p, Company c
WHERE p.worksfor = c.nameUnintuitive Query
SELECT DISTINCT R.A
FROM R, S, T
WHERE R.A=S.A OR R.A=T.A
다음과 같은 Query문은 주황색 부분의 정보를 나타내는데 여기서 R, S, T 중 하나가 \( \phi \)이라면 결과가 \( \phi \)이 나오기 때문에 table이 공집합이 아닌지 검사해야 한다.
'데이터베이스' 카테고리의 다른 글
| [DBMS] Transactions에서 ACID를 유지하는 방법 logging, Locking (0) | 2023.05.30 |
|---|---|
| [DBMS] Transactions을 사용하는 이유(ACID) (0) | 2023.05.30 |
| [SQL] Multiset Operations, 중첩 질의문, 집합 연산, NULL JOIN (0) | 2023.04.18 |
| [SQL]DBMS란 무엇인가? (0) | 2023.04.17 |
SQL
SQL(Structured Query Language)은 Relational database에 정보를 저장하고 처리하기 위해 쓰이는 프로그래밍 언어로 SQL문을 사용하면 데이터베이스에서 정보를 저장, 업데이트, 제거, 검색할 수 있고 Python과 같은 high-level 언어이다.
DDL(Data Definition Language), DML(Data Manipulation Language), DCL(Data Control Language), TCL(Transaction Control Language)가 있음
| 명령어 종류 | 명령어 | 설명 |
| 데이터 조작어 DML |
SELECT(=RETRIEVE) | 데이터베이스의 데이터를 조회하거나 검색하기 위한 명령어 |
| INSERT UPDATE DELETE |
데이터베이스의 테이블에 있는 데이터를 변형하는 명령어 삽입, 수정, 삭제 |
|
| 데이터 정의어 DDL |
CREATE ALTER DROP RENAME TRUNCATE |
테이블과 같이 데이터 구조를 정의하는데 사용하는 명령어 생성, 변경, 삭제, 이름변경 |
| 데이터 제어어 DCL |
GRANT REVOKE |
데이터베이스에 접근하고 객체들을 사용할 수 있도록 권한을 주고 회수하는 명령어 |
| 트랜잭션 제어어 TCL |
COMMIT ROLLBACK SAVEPOINT |
논리적인 작업 단위를 묶어서 DML에 의해 조작된 결과를 작업단위(트랜잭션)별로 제어하는 명렁어 |
Table
Relation과 Table은 schema로 지정된 속성을 가지는 tuples의 다중집합(Multiset)이다.
Multiset
Multiset이란 중복을 허용하며 순서가 없는 자료형으로 list, set과 비교하면 쉽게 이해할 수 있다.
| 중복 | 순서 | |
| List | O | O |
| Set | X | X |
| Multiset | O | X |
용어
Attribute
- 속성으로 Column이라고도 불리며 각 tuple에 있는 입력된 데이터의 항목이다.
- Attribute는 Atomic을 가져야 하는데 이는 하나의 Attribute에는 하나의 정보만 들어가야 한다. 예를 들어 이름과 나이 정보를 하나의 Attribute에 적을 수 없다.
Tuple
- row, record라고도 불리며 스키마에 의해 지정된 속성을 가진 테이블의 단일 항목이다.
Cardinality
- Tuple의 수이다
Arity
- Attribute의 수이다.
모든 Attribute는 atomic type을 가져야 하며 Atomic types는 아래와 같다.
| Characters | CHAR(20), VARCHAR(50) |
| Numbers | INT, BIGINT, SMALLINT, FLOAT |
| Others | MONEY, DATETIME |
Schema
Table에서 Schema는 테이블 이름, attributes, types이다.
Product(Pname: String, Price: float, Category: String, Manufacturer: string)
Key
Attribute중 unique 한 값을 가지는 것으로 주로 밑줄이 그어져 있다. 이는 Key는 해당 table의 모든 tuple을 유일하게 구별할 수 있음을 뜻한다.
Students(sid: string, name: string, gpa: float)
sid가 key가 될 수 있으며, Key는 가능하면 있도록 설계하는 것이 좋고 이는 DBA의 몫이다. Key는 여러 개 설정할 수 있지만 이를 쌍으로 유지해야 한다.
NULL
NULL 은 '0' 없음을 뜻하고 값이 안정해진 상태를 의미한다. 하지만 Key는 모든 tuple을 유일하게 구별할 수 있어야 하기 때문에 NULL 값이 들어가면 안 되고 이는 Constrain을 통해 해결할 수 있다.
SQL Query
SELECT
가장 기본적인 Query문으로 데이터를 불러오는 역할을 하며 SFW로 외워서 사용한다.
SELECT <attributes>
FROM <one or more relations>
WHERE <conditions>
Product에서 Category가 'Gadgets'인 tuple 중모든 Attributes 정보를 가져와라
SELECT *
FROM Product
WHERE Category = 'Gadgets'Product에서 Category가 'Gadgets'인 tuple 중 PName, Price, Manufacturer 정보를 가져와라
이때 Attribute의 정렬 순서는 SELECT에 적은 순서대로 정렬된다.
SELECT PName, Price, Manufacturer
FROM Product
WHERE Category = 'Gadgets'여기서 우리는 Input Schema와 Output Schema가 다르다는 것을 알아야 함
| Input Schema | Product(PName, Price, Category, Maufacturer) |
| Output Schema | Answer(PName, Price, Manfacturer) |
Output Schema는 SQL Query를 통해 나온 한정된 table이다.
변수 이름 규칙
- SQL의 명령어는 대소문자를 구분하지 않음
- SELECT = Select = select
- Product = product
- Values의 이름은 대소문자를 구분함
- Seattle \( \neq \)seattle
- 문자열은 무조건 Sigle quetes를 사용해야 한다
- 'hello' (O)
- "hello" (X)
LIKE
LIKE연산자는 문자열의 패턴을 검색하는 데 사용한다.
SELECT *
FROM Table
WHERE Att LIKE 'PATTERN'Pattern을 감지하기 위해 % 와 _를 사용한다.
- %는 몇 글자든 상관없이 모든 문자를 확인하라는 의미이다,
- _는 한 글자만 확인하라는 의미이다.
| 1. AgizmoA | 2. AAgizmoA |
2가지의 단어가 있다고 했을 때 % gizmo%는 2개의 문자열을 인식할 수 있고 _gizmo%는 1번 하나의 문자열을 인식할 수 있다.
DISTINCT
중복된 값을 Unique 하게 만드는 연산자이다.
SELECT Category
FROM ProductSELECT DISTINCT Category
FROM ProductORDER BY
table의 attibute를 정렬하는 명령어이고 기본적으로 오름차순으로 되어있다.
SELECT *
FROM Table
WHERE Att1
ORDER BY Att2SELECT PName, Price
FROM Product
WHERE Category='gizmo'
ORDER BY Price, PName내림차순으로 보고 싶다면 DESC키워드를 사용하면 됨
SELECT PName, Price
FROM Product
WHERE Category='gizmo'
ORDER BY Price, PName DESCForeign Key
외래키(Foregin Key)란 두 테이블을 연결하는 데 사용하는 키이고 외래키가 포함된 테이블을 자식테이블, 외래키를 제공하는 테이블을 부모 테이블이라고 부른다.
자식테이블은 부모테이블에 의존성을 가지고 있으며 constraint를 가지고 있다.
constraint
외래키의 Att는 부모테이블에 존재하는 값으로만 지정해야 한다.
Enrolled의 student_id는 외래키로 Students의 sid에 의존성을 지닌다. 여기서 Enrolled.student_id의 값은 Students.sid에 의존하기 때문에 Students.sid에 존재하는 값으로만 지정되어야 한다.
여기서 Students의 한 학생 tuple을 지우고 싶다면 우선 의존성을 검사한 뒤 삭제한 학생 정보를 가진 student_id tuple을 다 삭제한 뒤에 sid를 삭제할 수 있고 NULL값이 있다면 자동으로 무시된다.
Company의 CName이 삭제된다면 Product의 Manufacturer도 자동으로 삭제된다.
선언
위의 Enrolled은 CREATE 명령문을 통해 아래와 같은 코드로 생성할 수 있다.
CREATE TABLE Enrolled(
student_id CHAR(20),
cid CHAR(20),
grade CHAR(10),
PRIMARY KEY (student_id, cid),
FOREIGN KEY (student_id) REFERENCES Students(sid)
)Joins
Joins은 두 개 이상의 테이블 사이의 관련 열을 기반으로 행을 결합하여 의미 있는 정보를 추출하는 데에 사용한다.
Product(PName, Price, Category, Manufacturer)
Company(CName, StockPrice, Country)위의 2개의 테이블이 있을 때 일본에서 생산되고 가격은 200불 이하인 제품을 찾으시오.
# 1 Join없이 구현
SELECT PName, Price
FROM Product, Company
WHERE Manufacturer = CName
AND Country=‘Japan’
AND Price <= 200# Join으로 구현
SELECT PName, Price
FROM Product
JOIN Company ON Manufacturer = Cname // Product를 기준으로 Company를 Join함
AND Country=‘Japan’
WHERE Price <= 200위의 문제는 하나의 테이블로는 해결할 수 없기에 2개의 테이블을 join 하여 문제를 해결한다.
Join은 2개의 table을 하나로 묶어줄 연결고리가 필요하고 위의 코드에서는 Manufacturer = CName가 그 역할을 한다.
Ambiguity
서로 다른 table의 Att가 같을 경우 모호성이 생기기 때문에 명시적으로 바꿔줘야 한다.
Person(name, address, worksfor)
Company(name, address)명시적 표기
SELECT DISTINCT Person.name, Person.address
FROM Person, Company
WHERE Person.worksfor = Company.name약어 표기
SELECT DISTINCT p.name, p.address
FROM Person p, Company c
WHERE p.worksfor = c.nameUnintuitive Query
SELECT DISTINCT R.A
FROM R, S, T
WHERE R.A=S.A OR R.A=T.A다음과 같은 Query문은 주황색 부분의 정보를 나타내는데 여기서 R, S, T 중 하나가 \( \phi \)이라면 결과가 \( \phi \)이 나오기 때문에 table이 공집합이 아닌지 검사해야 한다.
'데이터베이스' 카테고리의 다른 글
| [DBMS] Transactions에서 ACID를 유지하는 방법 logging, Locking (0) | 2023.05.30 |
|---|---|
| [DBMS] Transactions을 사용하는 이유(ACID) (0) | 2023.05.30 |
| [SQL] Multiset Operations, 중첩 질의문, 집합 연산, NULL JOIN (0) | 2023.04.18 |
| [SQL]DBMS란 무엇인가? (0) | 2023.04.17 |