
-
Optimizer
-
학습률
-
확률적 경사하강법(Stochastic Gradient Descent)
-
수식
-
SGD문제
-
고정학습률 문제
-
협곡 문제
-
안장점 문제
-
문제 해결 방법
-
SGD 모멘텀 (SGD Momentum)
-
핵심 개념
-
수식
-
오버 슈팅 문제 Overshooting
-
네스테로프 모멘텀(Nesterov Momentum)
-
핵심 개념
-
수식
-
그레이디언트 계산 트릭
-
AdaGrad(Adaptive gradient)
-
핵심 개념
-
수식
-
문제점
-
RMSProp(Root mean square propagation)
-
수식
-
Adam(Adaptive moment estimation)
-
수식
-
문제점
Optimizer

학습률
최적화를 진행할 때 한 걸음의 폭을 결정하는 Step size이다. 학습률이 크다면 최적해에 빠르게 도달하고 작다면 느리게 도달함
확률적 경사하강법(Stochastic Gradient Descent)
손실 함수의 곡선에서 경사가 가장 가파른 곳으로 내려가다 보면 언젠가 가장 낮은 지점에 도달한다는 가정으로 만들어졌다. 알고리즘의 가정이 단순한 만큼 다양한 상황에 쓰기 못하고 학습 속도도 느리고 성능의 한계도 존재함
고정된 학습률을 사용하기 때문에 경험에 의존하여 학습률을 지정해야 한다. 감과 경험에 의존하여 학습률을 구하기 때문에 효율적이지 못함
수식
$$ x_{t} = x_{t-1} - lr * \nabla f(x_{t-1}) $$


SGD문제
고정학습률 문제
학습률이 작다면 최적해로 수렴하는데 오랜 시간이 걸리고 학습률이 크다면 최적해로 수렴하지 못하고 손실이 커지는 방향으로 발산할 수 있음

협곡 문제
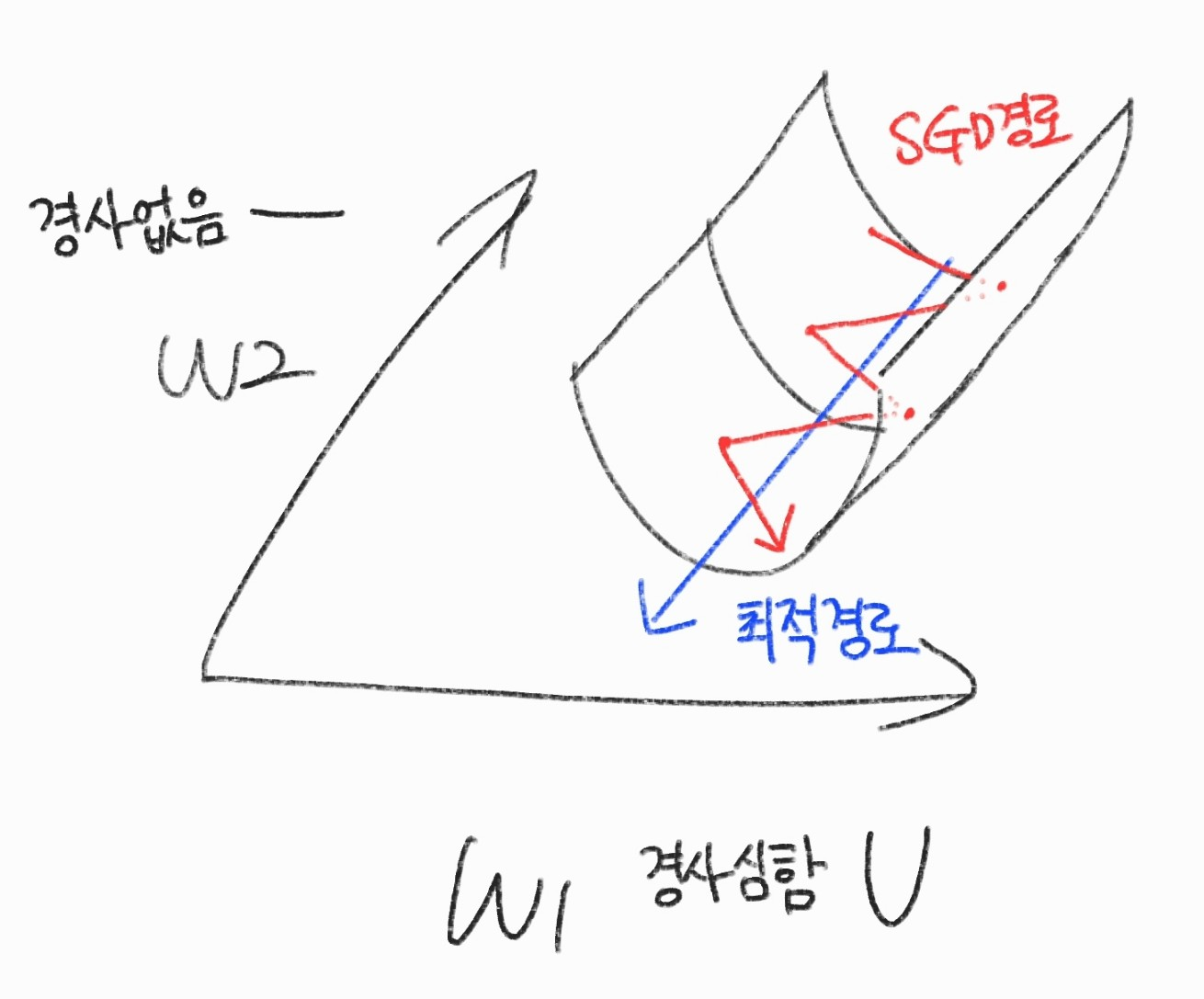
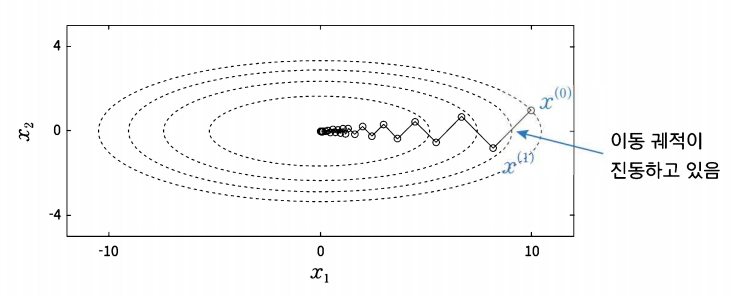
협곡의 등고선을 보면 장축은 길로 단축을 짧은 타원형 모양이 된다. \( w_{1} \)에서는 경사가 심하기 때문에 loss이 적은 방향으로 움직이기 위해 지그재그 형식으로 움직이며(학습률이 고정되어 있기 때문에), \( w_{2} \)에서는 경사가 거의 없기 때문에 그냥 loss가 낮아지는 방향으로 이동함
손실함수의 표면이 거칠더라도 민감하게 경로를 바꾸면 안 됨
안장점 문제
손실 함수 곡면에서 임계점(Critical point)은 미분값이 0인 지점에서 최대점(Maximum point), 최소점(Minimum point), 안장점(Saddle point)이 됨
안장점은 한쪽축에서는 최소인데 다른 축에서는 최대인 지점임
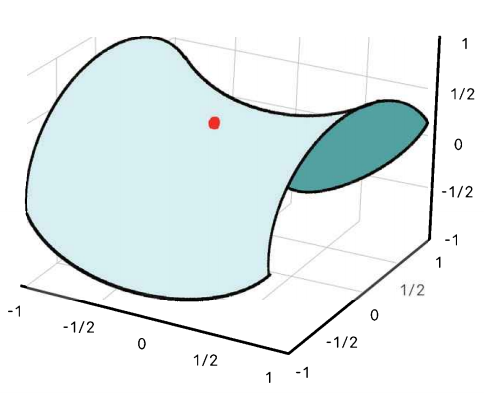
SGD는 임계점을 만나면 학습을 종료하기 때문에 안장점을 만나도 학습을 계속 진행할 수 있는 방법이 필요하다.
문제 해결 방법
학습률 감소 Learning rate decay
일반적으로 학습 초기에는 빠르게 최적해를 찾기 위해 큰 Step size로 내려가고, 어느 정도 내려갔다면 작은 Step size로 천천히 이동하여 최적해를 찾을 수 있게 함
적응적 학습률 Adaptive learning rate
경사가 가파를 때 큰 폭으로 이동하면 최적화 경로를 벗어나거나 최적해를 지나칠 수 있으므로 경사가 완만하다면 빠르게, 경사가 급격하다면 느리게 이동하는 것이 좋음
따라서 곡면의 변화에 따라 학습률을 적응적으로 조정한다면 안정적으로 학습할 수 있음
SGD 모멘텀 (SGD Momentum)
최적해를 향해 진행하던 속도에 관성을 주어 SGD의 느린 학습 속도와 협곡과 안장점을 만났을 때 학습이 안 되는 문제, 거친 표면에서 진동하는 문제를 해결한 최적화 알고리즘
핵심 개념

SGD가 가장 가파른 곳으로 내려가는 알고리즘이라면 SGD 모멘텀은 지금까지 진행하던 속도에 관성이 작용하도록 만든 방식이다. 속도 벡터는 현재 이동하는 속도임
이렇게 속도 벡터가 생기면 방향을 급격하게 바꾸지 않고 학습하면서 관성이 생겨 학습 경로가 매끄러워지고 가파른 경사를 만나면 가속도가 생겨 학습 손도가 빨라짐


수식
$$v_{t} = \rho v_{t-1}+ \alpha \nabla f(x_{t-1}) $$
$$ x_{t} = x_{t-1} - v_{t} $$
- \( v \) : momentum의 속도
- \( \rho \) : 관성 계수 (momentum term) 보통 0.9, 0.99를 사용함
- \( \alpha \) : 학습률 (Learning rate)



오버 슈팅 문제 Overshooting
경사가 가파른 곳에서 빠른 속도로 내려오다 최적해를 만나면 Gradient는 순간적으로 작아지지만 속도는 크기 때문에 최소 점을 지나치는 문제
최적해가 평평한 곳에 있다면 이와 같은 문제를 막을 수 있지만, 그렇지 않다면 최적해 근처를 평평하게 해주는 정규화 기법을 사용하면 됨
네스테로프 모멘텀(Nesterov Momentum)
관성을 이용해서 현재 속도로 한걸음 미리 간 지점에서 내리막기로 내려가는 방식이다. 오버 슈팅이 생기지 않도록 하기 위해서 미리 한 걸음 갔을 때 높이 올라간 만큼 다시 내려오도록 그레디언트를 교정해 줌
핵심 개념

네스테로프 모멘텀은 현재의 속도 벡터와 현재 속도로 한걸음 미리 가본 위치의 그레이디언트를 더해서 다음 위치를 구함
수식
$$ v_{t+1} = \rho v_{t}-\alpha \triangledown f(x_{t}+\rho v_{t}) $$
$$ x_{t+1} = x_{t}+v_{t+1} $$
- \( v \) : momentum의 속도
- \( \rho \) : 관성 계수 (momentum term) 보통 0.9, 0.99를 사용함
- \( \alpha \) : 학습률 (Learning rate)


그레이디언트 계산 트릭
한 걸음 미리 가 본 지점의 그레이디언트를 계산하기 위해서는 한걸음 미리 갔다가 돌아와야 하기 때문에 계산이 조금 복잡함

AdaGrad(Adaptive gradient)
손실 함수의 곡면의 변화에 따라 적응적으로 학습률을 정하는 알고리즘
핵심 개념

변화가 크면 작은 폭으로 이동하고 변화가 작으면 큰 폭으로 이동한다. 그렇게 하기 위해서는 변화량에 학습률이 적응적으로 조정되어야 함
- 곡면의 변화량이 크다 -> 기울기의 변화가 크다.
- 곡면의 변화량이 작다 -> 기울기의 변화가 작다.
기울기 벡터
$$ (\bigtriangledown f(x_{1}), \bigtriangledown f(x_{2}),\bigtriangledown f(x_{3}),\cdots ,\bigtriangledown f(x_{t})) $$
곡면의 변화량
$$ r_{t+1} = \bigtriangledown f(x_{1})^{2}+ \bigtriangledown f(x_{2})^{2}+\bigtriangledown f(x_{3})^{2}+\cdots +\bigtriangledown f(x_{t})^{2} $$
수식
$$ r_{t+1} = r_{t}+ \nabla f(x_{t})^{2} $$
$$ x_{t+1}=x_{t}- \frac{ \alpha }{ \sqrt[]{r_{t+1}+ \epsilon }} \odot \nabla f(x_{t}) $$
문제점

곡선의 변화량이 커졌다가 작아지면 학습률도 작아졌다 커져야 하는데 커지지 않아 훈련 초반에 학습이 중단됨
RMSProp(Root mean square propagation)

최근 경로의 곡면 변화량에 따라 학습률을 적응적으로 결정하는 알고리즘
AdaGrad의 문제점을 보완한 것으로 전체 경로가 아닌 최근 경로의 변화량을 측정하면 곡면 변화량이 누적되어 계속 증가하는 현상을 없앨 수 있음
수식
$$ r_{t+1} = \beta r_{t}+(1- \beta ) \nabla f(x_{t})^{2} $$
$$ x_{t+1} = x_{t}- \frac{ \alpha }{ \sqrt{r_{t+1}+ \epsilon }} \odot \nabla f(x_{t}) $$
- \( \beta \)는 보통 0.9를 사용하며, \( \epsilon \)은 분모가 0이 되지 않게 더해주는 아주 작은 상수임(1e-8)

gradient 제곱에 곱해지는 가중치가 지수승으로 변화하며 단계마다 gradient 제곱의 비율을 반영하여 평균이 업데이트되기 때문에 지수가중이동평균이라고 부름
Adam(Adaptive moment estimation)
SGD 모멘텀과 PMSProp이 결합한 형태로 진행하던 속도에 관성을 줌과 동시에 최근 경로의 곡면의 변화량에 따라 적응적 학습률을 갖는 알고리즘
Adam은 관성에 대한 장점과 적응적 학습률에 대한 장점을 모두 갖는 전략을 취하기 때문에 최적화 성능이 우수하고 잡음 데이터에 대해 민감하게 반응하지 않는 성질이 있음
수식
$$ v_{t+1} = \beta_{1}v_{t}+(1-\beta_{1})\nabla f(x_{t}) $$
$$ r_{t+1} = \beta_{2}r_{t}+(1-\beta_{2})\nabla f(x_{t})^{2} $$
$$ x_{t+1}=x_{t}-\frac{\alpha}{\sqrt{r_{t+1}+\epsilon}}\bigodot v_{t+1} $$

문제점
초기 경로 편향 문제가 발생함
파라미터 값이 0이기 때문에 이러한 형상이 발생함

이를 보완하기 위해서
$$ v_{t+1} = \frac{v_{t+1}}{(1- \beta ^{t}_{1})} ,r_{t+1} = \frac{r_{t+1}}{(1-\beta ^{t}_{2})} $$
이렇게 식을 보완함
'Machine Learning > 기법' 카테고리의 다른 글
| [ML] 머신러닝 Machine Learning 앙상블 Ensemble (0) | 2023.01.17 |
|---|---|
| [ML] 정규화 (0) | 2023.01.16 |
| [ML] 손실 함수 (0) | 2023.01.10 |
| [ML] 경사하강법 (0) | 2023.01.09 |
| [ML] 회귀 모델 (0) | 2023.01.04 |
Optimizer
학습률
최적화를 진행할 때 한 걸음의 폭을 결정하는 Step size이다. 학습률이 크다면 최적해에 빠르게 도달하고 작다면 느리게 도달함
확률적 경사하강법(Stochastic Gradient Descent)
손실 함수의 곡선에서 경사가 가장 가파른 곳으로 내려가다 보면 언젠가 가장 낮은 지점에 도달한다는 가정으로 만들어졌다. 알고리즘의 가정이 단순한 만큼 다양한 상황에 쓰기 못하고 학습 속도도 느리고 성능의 한계도 존재함
고정된 학습률을 사용하기 때문에 경험에 의존하여 학습률을 지정해야 한다. 감과 경험에 의존하여 학습률을 구하기 때문에 효율적이지 못함
수식
$$ x_{t} = x_{t-1} - lr * \nabla f(x_{t-1}) $$
SGD문제
고정학습률 문제
학습률이 작다면 최적해로 수렴하는데 오랜 시간이 걸리고 학습률이 크다면 최적해로 수렴하지 못하고 손실이 커지는 방향으로 발산할 수 있음
협곡 문제
협곡의 등고선을 보면 장축은 길로 단축을 짧은 타원형 모양이 된다. \( w_{1} \)에서는 경사가 심하기 때문에 loss이 적은 방향으로 움직이기 위해 지그재그 형식으로 움직이며(학습률이 고정되어 있기 때문에), \( w_{2} \)에서는 경사가 거의 없기 때문에 그냥 loss가 낮아지는 방향으로 이동함
손실함수의 표면이 거칠더라도 민감하게 경로를 바꾸면 안 됨
안장점 문제
손실 함수 곡면에서 임계점(Critical point)은 미분값이 0인 지점에서 최대점(Maximum point), 최소점(Minimum point), 안장점(Saddle point)이 됨
안장점은 한쪽축에서는 최소인데 다른 축에서는 최대인 지점임
SGD는 임계점을 만나면 학습을 종료하기 때문에 안장점을 만나도 학습을 계속 진행할 수 있는 방법이 필요하다.
문제 해결 방법
학습률 감소 Learning rate decay
일반적으로 학습 초기에는 빠르게 최적해를 찾기 위해 큰 Step size로 내려가고, 어느 정도 내려갔다면 작은 Step size로 천천히 이동하여 최적해를 찾을 수 있게 함
적응적 학습률 Adaptive learning rate
경사가 가파를 때 큰 폭으로 이동하면 최적화 경로를 벗어나거나 최적해를 지나칠 수 있으므로 경사가 완만하다면 빠르게, 경사가 급격하다면 느리게 이동하는 것이 좋음
따라서 곡면의 변화에 따라 학습률을 적응적으로 조정한다면 안정적으로 학습할 수 있음
SGD 모멘텀 (SGD Momentum)
최적해를 향해 진행하던 속도에 관성을 주어 SGD의 느린 학습 속도와 협곡과 안장점을 만났을 때 학습이 안 되는 문제, 거친 표면에서 진동하는 문제를 해결한 최적화 알고리즘
핵심 개념
SGD가 가장 가파른 곳으로 내려가는 알고리즘이라면 SGD 모멘텀은 지금까지 진행하던 속도에 관성이 작용하도록 만든 방식이다. 속도 벡터는 현재 이동하는 속도임
이렇게 속도 벡터가 생기면 방향을 급격하게 바꾸지 않고 학습하면서 관성이 생겨 학습 경로가 매끄러워지고 가파른 경사를 만나면 가속도가 생겨 학습 손도가 빨라짐
수식
$$v_{t} = \rho v_{t-1}+ \alpha \nabla f(x_{t-1}) $$
$$ x_{t} = x_{t-1} - v_{t} $$
- \( v \) : momentum의 속도
- \( \rho \) : 관성 계수 (momentum term) 보통 0.9, 0.99를 사용함
- \( \alpha \) : 학습률 (Learning rate)
오버 슈팅 문제 Overshooting
경사가 가파른 곳에서 빠른 속도로 내려오다 최적해를 만나면 Gradient는 순간적으로 작아지지만 속도는 크기 때문에 최소 점을 지나치는 문제
최적해가 평평한 곳에 있다면 이와 같은 문제를 막을 수 있지만, 그렇지 않다면 최적해 근처를 평평하게 해주는 정규화 기법을 사용하면 됨
네스테로프 모멘텀(Nesterov Momentum)
관성을 이용해서 현재 속도로 한걸음 미리 간 지점에서 내리막기로 내려가는 방식이다. 오버 슈팅이 생기지 않도록 하기 위해서 미리 한 걸음 갔을 때 높이 올라간 만큼 다시 내려오도록 그레디언트를 교정해 줌
핵심 개념
네스테로프 모멘텀은 현재의 속도 벡터와 현재 속도로 한걸음 미리 가본 위치의 그레이디언트를 더해서 다음 위치를 구함
수식
$$ v_{t+1} = \rho v_{t}-\alpha \triangledown f(x_{t}+\rho v_{t}) $$
$$ x_{t+1} = x_{t}+v_{t+1} $$
- \( v \) : momentum의 속도
- \( \rho \) : 관성 계수 (momentum term) 보통 0.9, 0.99를 사용함
- \( \alpha \) : 학습률 (Learning rate)
그레이디언트 계산 트릭
한 걸음 미리 가 본 지점의 그레이디언트를 계산하기 위해서는 한걸음 미리 갔다가 돌아와야 하기 때문에 계산이 조금 복잡함
AdaGrad(Adaptive gradient)
손실 함수의 곡면의 변화에 따라 적응적으로 학습률을 정하는 알고리즘
핵심 개념
변화가 크면 작은 폭으로 이동하고 변화가 작으면 큰 폭으로 이동한다. 그렇게 하기 위해서는 변화량에 학습률이 적응적으로 조정되어야 함
- 곡면의 변화량이 크다 -> 기울기의 변화가 크다.
- 곡면의 변화량이 작다 -> 기울기의 변화가 작다.
기울기 벡터
$$ (\bigtriangledown f(x_{1}), \bigtriangledown f(x_{2}),\bigtriangledown f(x_{3}),\cdots ,\bigtriangledown f(x_{t})) $$
곡면의 변화량
$$ r_{t+1} = \bigtriangledown f(x_{1})^{2}+ \bigtriangledown f(x_{2})^{2}+\bigtriangledown f(x_{3})^{2}+\cdots +\bigtriangledown f(x_{t})^{2} $$
수식
$$ r_{t+1} = r_{t}+ \nabla f(x_{t})^{2} $$
$$ x_{t+1}=x_{t}- \frac{ \alpha }{ \sqrt[]{r_{t+1}+ \epsilon }} \odot \nabla f(x_{t}) $$
문제점
곡선의 변화량이 커졌다가 작아지면 학습률도 작아졌다 커져야 하는데 커지지 않아 훈련 초반에 학습이 중단됨
RMSProp(Root mean square propagation)
최근 경로의 곡면 변화량에 따라 학습률을 적응적으로 결정하는 알고리즘
AdaGrad의 문제점을 보완한 것으로 전체 경로가 아닌 최근 경로의 변화량을 측정하면 곡면 변화량이 누적되어 계속 증가하는 현상을 없앨 수 있음
수식
$$ r_{t+1} = \beta r_{t}+(1- \beta ) \nabla f(x_{t})^{2} $$
$$ x_{t+1} = x_{t}- \frac{ \alpha }{ \sqrt{r_{t+1}+ \epsilon }} \odot \nabla f(x_{t}) $$
- \( \beta \)는 보통 0.9를 사용하며, \( \epsilon \)은 분모가 0이 되지 않게 더해주는 아주 작은 상수임(1e-8)
gradient 제곱에 곱해지는 가중치가 지수승으로 변화하며 단계마다 gradient 제곱의 비율을 반영하여 평균이 업데이트되기 때문에 지수가중이동평균이라고 부름
Adam(Adaptive moment estimation)
SGD 모멘텀과 PMSProp이 결합한 형태로 진행하던 속도에 관성을 줌과 동시에 최근 경로의 곡면의 변화량에 따라 적응적 학습률을 갖는 알고리즘
Adam은 관성에 대한 장점과 적응적 학습률에 대한 장점을 모두 갖는 전략을 취하기 때문에 최적화 성능이 우수하고 잡음 데이터에 대해 민감하게 반응하지 않는 성질이 있음
수식
$$ v_{t+1} = \beta_{1}v_{t}+(1-\beta_{1})\nabla f(x_{t}) $$
$$ r_{t+1} = \beta_{2}r_{t}+(1-\beta_{2})\nabla f(x_{t})^{2} $$
$$ x_{t+1}=x_{t}-\frac{\alpha}{\sqrt{r_{t+1}+\epsilon}}\bigodot v_{t+1} $$
문제점
초기 경로 편향 문제가 발생함
파라미터 값이 0이기 때문에 이러한 형상이 발생함
이를 보완하기 위해서
$$ v_{t+1} = \frac{v_{t+1}}{(1- \beta ^{t}_{1})} ,r_{t+1} = \frac{r_{t+1}}{(1-\beta ^{t}_{2})} $$
이렇게 식을 보완함
'Machine Learning > 기법' 카테고리의 다른 글
| [ML] 머신러닝 Machine Learning 앙상블 Ensemble (0) | 2023.01.17 |
|---|---|
| [ML] 정규화 (0) | 2023.01.16 |
| [ML] 손실 함수 (0) | 2023.01.10 |
| [ML] 경사하강법 (0) | 2023.01.09 |
| [ML] 회귀 모델 (0) | 2023.01.04 |